آمار به زبان ساده – آزمون فرضیه با دو نمونه
03 مهر 1400
دقیقه
يك آموزگار از الگوي جديدي براي خواندن كه در كشور ديگر معرفي شده آگاه ميشود و ميخواهد بداند كه اين الگو در اينجا كاربرد دارد يا خير. گزارشهايي در مطالب چاپي آموزشي آن كشور مدعي بود اين الگوي جديد ، موجب كارآيي بهتر كودكان در خواندن شده است. مشكل اين بود كه اين دادهها متعلق...

آخرین بهروزرسانی: 24 دی 1401
يك آموزگار از الگوي جديدي براي خواندن كه در كشور ديگر معرفي شده آگاه ميشود و ميخواهد بداند كه اين الگو در اينجا كاربرد دارد يا خير. گزارشهايي در مطالب چاپي آموزشي آن كشور مدعي بود اين الگوي جديد ، موجب كارآيي بهتر كودكان در خواندن شده است. مشكل اين بود كه اين دادهها متعلق به زبانی ديگر بود. اين معلم ميخواست بداند كه آيا اين الگوي جديد بهتر از الگوي فعلي خواندن است كه اكنون كشورش به كار برده ميشود يا خير.
آموزگار تصميم گرفت در كلاس بعدي كه ميگيرد نصف كودكان را با روش جديد و نصف ديگر را با روش قديم آموزش دهد. كودكان به صورت تصادفي به دو الگو اختصاص داده شدند تا در نمونهها از بزرگنمايي در فاكتورهايي مثل هوش خودداري شده باشد بدين ترتيب پذيرفته شده كه كودكان به صورت سيستماتيك تنها در يك متغير مورد مطالعه يعني الگوي خواندن تفاوت دارند. آموزگار اكنون نمونهها را مقايسه ميكند. او واقعاً علاقهاي به خود نمونهها نداشت بلكه جمعيتي كه اين كودكان بعنوان نمونه از ميان آنها انتخاب شده بودند. مورد نظر او بود، آيا الگوي جديد براي كودكان در اين سن و نه فقط كودكان اين كلاس بهتر است؟ سوال اين است كه آیا توزيع جمعيت الگوي جديد كارآيي بهتري از الگوي قديم دارد؟ متأسفانه آموزگار جزئياتي از اين جمعيتها نداشت و هر دوی آنها ناشناخته بودند.
چگونه ميتوان از اين نمونهها براي آزمون فرض استفاده كرد؟ در ابتدا پيش از هر چيز ميتوانيم بپرسيم كه آيا اين نمونهها نمايانگر جمعيتي هستند كه ما ميخواهيم نتيجه را بر آنها تعميم دهيم. كودكان اين مدرسه چگونه انتخاب شدهاند؟ آنها از چه گروه اجتماعي هستند؟ اين فاكتورها ممكن است تعميم دادن را محدود كند. دوّم، ميتوانيم به كارآيي دو نمونه در يك آزمون خواندن نظر كنيم. اگرتفاوت بين دو نمونه كوچك باشد ميبايستي به وجود تفاوت در جمعيتها شك كنيم، اگر تفاوت زياد باشد ممكن است تصميم بگيريم كه يافتهها دلالت بر تفاوت احتمالی بين جمعيتها دارد. مشكلي كه در اين جا رخ مينمايد. اين است كه اين تفاوت بايد چقدر بزرگ باشد تا فرض صفر را رد كرده و تصميم بگيريم كه نمونهها واقعاً از جمعيتهايي با توزيعهاي گوناگون ميآيند.
به مشكل مذكور ميتوان به اين شكل حمله برد كه: اجازه دهيد فرض كنيم كه دو نمونه واقعاً از یك توزيع ميآيند و فرض صفر صحيح بوده و هيچ تفاوتي از نظر كارآيي خواندن بين دو جمعيت وجود ندارد. چه تفاوتهايي را ميبايستي ما تنها به صورت شانسي بين دو نمونه انتظار داشته باشيم؟ ميتوانيم با گرفتن ميانگين از هر نمونه ممكن با همان اندازهاي كه مورد نظر ماست و مقايسه آن با ميانگين هر نمونه ديگري ازهمين اندازه، پاسخ را بيابيم. اين تفاوتها (در ميانگين نمونهها) به ما ميگويد كه چه اختلافاتي بين نمونهها را وقتي كه فرض صفر صحيح است بايد انتظار داشته باشيم. اگر اين تفاوتها را رسم كنيم توزيعي از تفاوتهاي ميان ميانگينهاي نمونهها را بدست خواهيم آورد.
همانند توزيع ميانگين نمونهها اين توزيع نيز بنظر يك توزيع نرمال ميآيد و همچنان که میدانیم این توزیع يك توزيع نمونهگيري است. اگر اندازه نمونهها بزرگ باشد این مورد نیز مانند حالت قبل خواهد بود. ميانگين اين توزيع صفر خواهد بود زيرا وقتي ما از يك توزيع نمونه ميگيريم تفاوتها در حول صفر حلقه خواهند زد زيرا ميان اغلب ميانگين نمونهها تفاوتي نيست يا تفاوت بسيار كمي وجود دارد. تنها به ندرت زماني اختلاف زيادي موجود خواهد بود كه يك نمونه همه كودكان خوب در خواندن را در خود داشته وديگري همه كودكان ضعيف را شامل شده باشد.
توزيع تفاضل بين ميانگين نمونهها وقتي كه فرض صفر صحيح باشد در تصوير 8.1 نشان داده شده است.
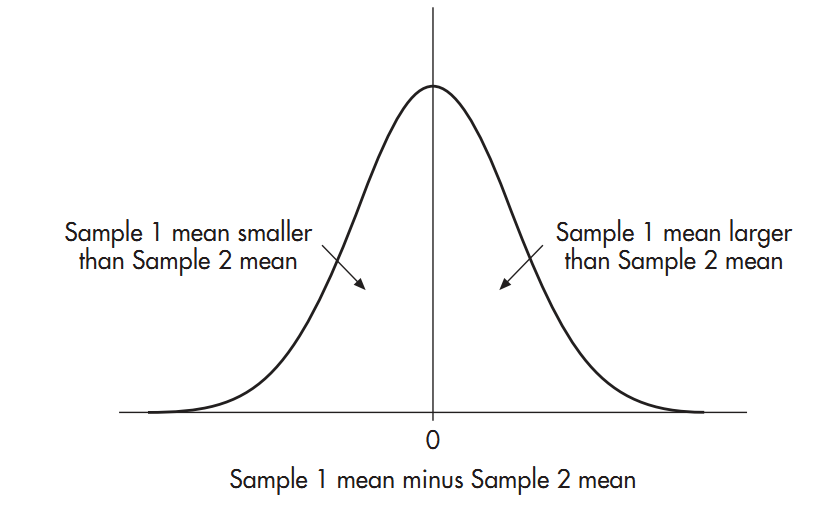
تصویر 8.1 توزيع تفاوتها بين ميانگين نمونهها
اكنون بنگر و ببين ما يك توزيع شناخته شده داريم يعني يك توزيع نرمال با يك ميانگين صفر. همچنين نمرهاي براي بررسي داريم يعني تفاضل ميانگين نمونهها، آزمون فرض، تماماً درباره مقايسه يك نمره با يك توزيع شناخته شده است.
اگر احتمال اینکه تفاضل میانگین نمونه های ما از توزیع شناخته شده (همان توزیع با میانگین صفر) بدست آمده اند بالا باشد، شانس اینکه فرض صفر درست باشد وجود دارد.
اگر احتمال کمی یافت شود که تفاضل میانگین نمونه های ما از توزیع شناخته شده موجود در کل جمعیت آمده اند، فرض صفر می تواند رد شود. تمام آنچه اكنون نياز داريم توليد يك نمره z (تفاضل ميان ميانگيننمونههايمان) بوده كه آنگاه ميتوانيم احتمال اين نمره را كه از توزيع شناخته شده است (توزيع تفاضل بين ميانگين نمونهها) بدست بياوريم تا ببينيم كه احتمال درست بودن فرض صفر چقدر است.



از فصل 6 به ياد بياوريد كه ما همه چيز را درباره توزيع t ميدانيم بنابراين قادر هستيم مقادير محتمل را در جدول بيابيم. نبايد فراموش كنيم كه توزيع t از درجه آزادي نمونهها تأثير ميپذيرد. يعني هر چه نمونهها بزرگتر باشند توزيع تقريباً به توزيع نرمال نزديكتر خواهد بود. اگر بخواهيم مقدار t محاسبه شده خودمان را با توزيع t درست مقايسه كنيم بايد درجه آزادي نمونههايمان را بدست بياوريم.

مفروضات آزمون t دو نمونهاي
مفروضات اساسي براي هر آزمون t هر چه كه ميخواهد باشد يكسان است. ما نيازمنديم كه توزيع نمونهگيريها به صورت نرمال باشد. بنابراين معمولاً فرض ميكنيم كه نمونههاي ما از جمعيتهاي با توزيع نرمال آمدهاند. خوشبختانه آزمون t بگونهاي محكم است كه اگر توزيعها فقط به صورت مبهم نرمال باشند يعني قوسي در ميانه و دنباله های اطراف داشته باشند، آنگاه آزمونt همچنان شايسته معتبر بودن است. اين به طور خاص در مورد نمونههاي بزرگ (بيشتر از 30) درست است. مجدداً ما بايد فرض كنيم كه نمونهها به صورت تصادفي از ميان جمعيتها برگزيده شدهاند تا بتوانيم آماره های نمونه (ميانگين، انحراف استاندارد) را بعنوان برآورد های نااریب از پارامترهاي جمعيت به كار ببريم. در انتهاي بايد فرض كنيم كه دو نمونه از جمعيتهاي با واريانس مساوي (و انحراف استاندارد مساوي چون يكي مربع ديگري است) آمدهاند تا بتوانيم اطلاعات نمونه را براي برآورد انحراف استاندارد جمعيت به كار ببريم. بنابراين فرض ميكنيم هر اثر متغير مستقل ، انتقال توزيع متغير غيرمستقل ، در طول مقیاس خواهد بود (يعني بر ميانگين جمعيت اثر ميگذارد) و تغييري در شكل جمعيت (واريانس يا انحراف استاندارد) آن نخواهد گذاشت.
نمونههاي مستقل يا نمونههاي وابسته
همانگونه كه در فصل پيشين ديديم نمونههاي مرتبط در موضوع ، نمراتي براي هر دو نمونه عرضه ميكنند در حاليكه با نمونههاي مستقل ، هر موضوع تنها با يك نمره فقط براي يك نمونه مشاركت ميكند. روشي كه ما بوسيله آن دو نمونه آزمون z را محاسبه ميكنيم بستگي به آن دارد كه آنها مستقل بوده يا وابسته باشند چون لازمه اين تفاوت ، فرمولهاي متفاوتي است. براي نمونه اگر ما 10 عنوان موضوعی در دو نمونه خود داشته باشيم در نمونههاي مرتبط و وابسته، تنها به 10 عنوان موضوعی نيازمنديم زيرا هر يك دوبار مورد استفاده قرارميگيرند در حاليكه با نمونههاي مستقل ما به 20 عنوان موضوعی يعني 10 عدد براي هر نمونه نياز داريم جزئيات اختلاف در فرمولها در زير خواهد آمد.
آزمون t وابسته
با فرمول خود براي t آغاز ميكنيم



یک مثال كار شده
يك آموزگار معتقد است كه شاگردان او صبحها در كارهايشان بهتر از بعدازظهر هستند. او تصميم گرفت اين مسئله را با يك امتحان رياضي كه نياز به تمركز دارد بيازمايد. اگر در كارآيي پس از نهار ، نزولي باشد اين آزمون باید آن را آشكار كند. او به صورت تصادفي يك نمونه 8 تايي از كودكان را برگزيده و به آنها دو آزمون با سختي يكسان داد. نمونهها براي جلوگيري از انتقال اثرات جانبي ديگر، بر روي دو نسخه از امتحان ، و زماني كه در ابتدا مورد آزمون قرار گرفتند ، تنظيم شدند. نمره آزمونها 10 بوده و نمره بالاتر نمايانگر كارايي بالاتري ميباشد. نتايج آزمونها به شرح ذيل بود:
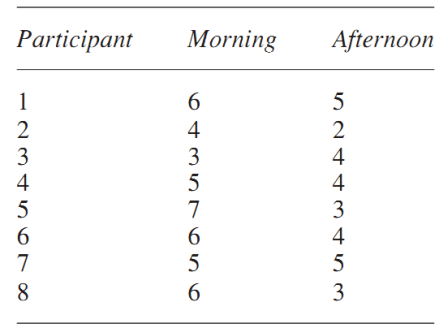

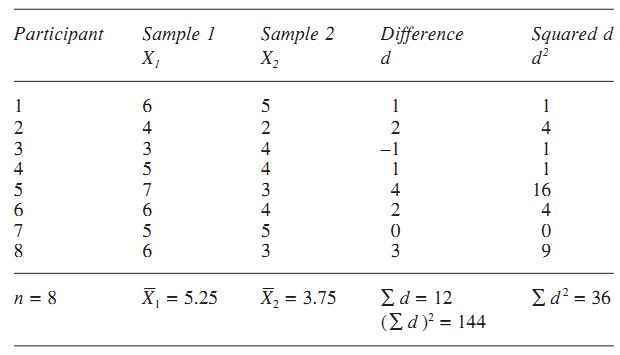

درجه آزادي براي آزمون t مرتبط هميشه n-1 بوده و بنابراين df=7 ميشود.
اين يك آزمون يك طرفه است زيرا پيش بيني بر آن بود كه كودكان در صبح كارآيي بهتري دارند و نمرات نمونه اول بزرگتر از نمونه دوم هستند. همانطور كه از ميانگينها ديده ميشود اين همان حالت است اما نياز است كه آزمون معنادار بودن اختلاف نمرات را انجام دهيم. در سطح معنی داری ، از جدول توزيع t (در ضميمه A.2) درمييابيم كه براي آزمون يك طرفه است.
مقدار محاسبه شده ما براي t براي 2.65 بزرگتر از مقدار 1.895 جدول است كه به ما اين اجازه را ميدهد که فرض صفر را در سطح معنی داری رد کرده و نتيجه بگيريم كه كودكان به طور معناداري در آزمون رياضي صبح كارآيي بهتري نسبت به آزمون رياضي بعدازظهر داشتند.
گاهي اوقات مقدار t محاسبه شده علامت منفي دارد. اين به سادگي بيانگر آن است كه ميانگين نمونه 1 كوچكتر از ميانگين نمونه 2 است. اگر ما در مثال بالا علامت منفي ميداشتيم ميبايستي پيشبيني يك طرفه را رد ميكرديم زيرا اين به معناي آن بود كه نمرات بعدازظهر بهتر بودهاند. اگر پيشبيني ما بر آن بود كه نمرات نمونه 2 بزرگتر خواهند بود و يا يك پيشبيني دو طرفه انجام ميداديم، در هنگام مقايسه مقدار محاسبه شده با مقدار جدول ، علامت منفي را ناديده ميگرفتيم.

مشكل ما براي ايجاد فرمولي براي t هنوز پايان نيافته است. ميدانيم كه هر چند اندازه نمونه بزرگتر باشد انحراف استاندارد نمونه برآورد بهتري از پارامتر جمعيت است و همچنين آزمون t فرض را بر اين ميگذارد كه نمونهها از جمعيتهايي با انحراف استاندارد يكسان ميآيند. بنابراین ميتوانيم نتيجه بگيريم وقتي نمونههايي با اندازههاي متفاوت داريم نمونه بزرگتر به احتمال زياد برآورد بهتري از نمونه كوچكتر براي انحراف استاندارد جمعیت است. آنچه که ما انجام می دهیم وزن دادن به میزان انحراف استاندارد های دو نمونه متناسب با اندازه هر نمونه است (بطور دقيقتر، واريانس آنها را با درجه آزاديشان) و يك برآورد جمعيت براساس میانگین وزنی انحراف استاندارد نمونهها توليد كنيم ، که باشد.


يك مثال کاربردی
آزمايش يك قرص خواب جديد براي روي تعداد داوطلب شروع شده است. پيشبيني ميشود كه اين قرص بر روي مردان و زنان اثرات متفاوتي داشته باشد. 6 مرد و 8 زن پذيرفتهاند كه در اين آزمايش مشاركت كنند. در مدت دو هفته به آنها يك دارو نما (قرصي كه تأثيري ندارد) يا قرص خواب داده شده است. شركتكنندگان نميدانند كه هر شب كدام يك از اين قرصها به آنها داده شده است. ساعت خواب اضافي افراد در هفت شب كه به آنها قرص خواب داده شده و در هفت شب كه شبه دارو و مصرف كردهاند محاسبه شده است مردان 4، 6، 5، 4 و5 و 6 ساعت و زنان 3، 8، 7، 6، 7 و 6 و7 و 6ساعت اضافه خوابيدهاند. آيا اين مويد پيشبيني ماست؟
براي يافتن t از فرمول بايد مقادير مورد نياز را پيدا كنيم.
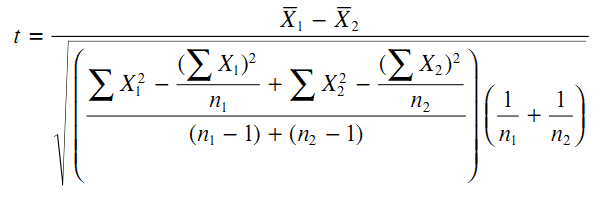
بايد مردان را به عنوان نمونه 1 و زنان را به عنوان نمونه 2 نامگذاری میكنيم .
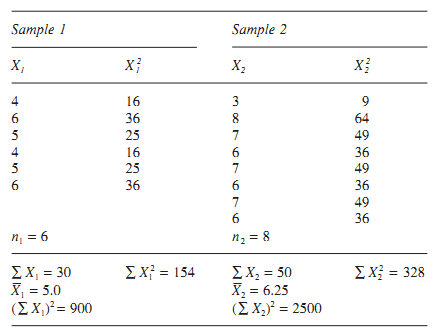
با وارد كردن ارقام در فرمول t مقدار آن حاصل ميشود:
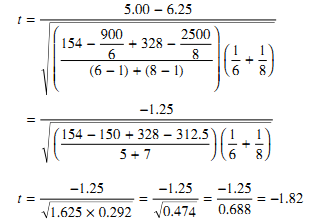
درجه آزادي نيز برابر 12 است با:
![]()
علامت منفي بيانگر بزرگتر بودن نمرات نمونه دوم (زنان) است. از آنجائيكه اين يك آزمون دو طرفه است آن را به عنوان 82/1+ تلقي مي کنيم. از جدول توزيع t (جدول A2 در ضميمه) بدست ميآيد كه:
از آنجائيكه مقدار t محاسبه شده بوسيله ما يعني 82/1 از مقدار جدول يعني 18/2 بزرگتر نيست نميتوانيم فرض صفر را رد كنيم: يعني تفاوت معناداري در ساعات خواب اضافي بين زنان و مردان در سطح معنی داری 5 درصد وجود ندارد.
بهرحال اين نتيجه جالبي است توجه كنيد تفاضل ميانگينها 25/1 به نفع زنان است. تفاضل ميانگينها به صورت شانسي به ميزان 688/0 مورد انتظار است (در بخش پائين محاسبه t) و حتي با وجود آنكه در اين معنادار نيست مقدار احتمال واقعي 0945/0 است كه هنوز مقدار كاملاً ناچيزي محسوب ميشود. ممكن است يك اثر واقعي زير سطح مورد نظر باشد اما اين اثر آنقدر قوي نيست كه از اين دادهها برداشت شود. اگر مشاركتكنندگان بيشتري داشتيم يا آزمونt يك طرفه بود شايد ميتوانستيم معنادار بودن را محقق كنيم. علت اين مسئله در فصل بعد تشريح خواهد شد.
بازههاي اطمينان
وقتي دو نمونه را مقايسه ميكنيم ميتوانيم بازههاي اطمينان را براي تفاضل در مقادير ميانگينها بدست آوريم. از فصل 6 به ياد بياوريد كه CI يا بازده اطمينان برابر است با تفاضل ميانگينها، بعلاوه منهاي حاصلضرب مقدار بحراني t در خطاي استاندارد تفاضل ميانگينها.

بعنوان مثال براي آزمون t مرتبط كه در اين فصل آمده، 95 درصد بازده اطمينان به شرح زير محاسبه ميشود.

در جدول براي در يك آزمون دو دمي با درجه آزادي مقدار بحراني t عدد را مييابيم. خطاي استاندارد محاسبه شده مخرج فرمول محاسبه مقدار t است. توجه داشته باشيد كه بازه شامل صفر نشده بنابراين ميتوانيم با اطمينان نتيجه بگيريم كه اختلاف ميانگينهاي نمونه صفر نبوده بلكه عددي مثبت است.
براي مثال در آزمون t مستقل ، بازه اطمينان 95 درصد به اين شكل محاسبه ميشود.
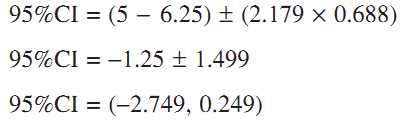
براي يك آزمون دو طرفه با مقدار بحراني t در جدول عدد 179. 2 یافت ميشود. مجدداً ميگوئيم مقدار ، خطاي استاندارد است که از محاسبه آزمون مربوط به گرفته ميشود. توجه كنيد كه در اين مثال بازه اطمينان شامل صفر ميشود. در اين حالت ما مطمئن نيستيم كه تفاوت واقعي در ميانگينها، غير از صفر باشد. همانگونه كه مقدار t به سطح معنادار بودن نرسيد، این مسئله در مورد فاصله اطمینان هم به همین صورت است، در حاليكه اغلب موارد نزدیک به صفر همچنان صفر را در خود دارند. هر دو تحليل به ما ميگويند كه شواهد كافي از دادهها براي ادعاي تفاوت در ميانگينهاي نمونه وجود ندارد.
مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




