آمار به زبان ساده – معنی داری، خطا و توان
11 مهر 1400
دقیقه
فهرست محتوا پنهان توان يك آزمون تأثيريگذاري اندازه اثر اندازه نمونه تصویر 9.1- خطای نوع اول و دوم اگر نمره ما زیر سطح معنی داری (عقب تر از آن) بیفتد فرض صفر پذیرفته می شود بدین معنی که توزیع ما یک توزیع شناخته شده است. چنانچه بار دیگر به نمودار 9.1 نگاه کنیم در میابیم...

آخرین بهروزرسانی: 24 دی 1401

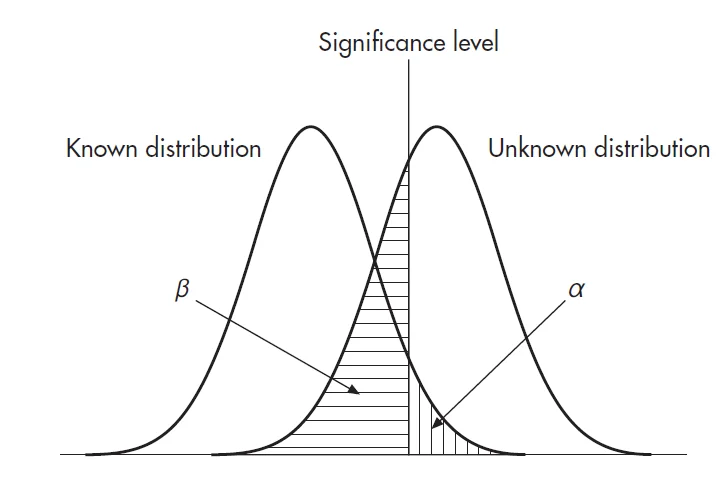
تصویر 9.1- خطای نوع اول و دوم
اگر نمره ما زیر سطح معنی داری (عقب تر از آن) بیفتد فرض صفر پذیرفته می شود بدین معنی که توزیع ما یک توزیع شناخته شده است. چنانچه بار دیگر به نمودار 9.1 نگاه کنیم در میابیم که در 95 درصد از موارد توزیع شناخته شده زیر سطح معنی داری قرار می گیرد. همچنین زیر سطح معنی داری بیشتر از اینکه توزیع ناشناخته داشته باشیم توزع شناخته داریم، بنابراین این احتمال وجود دارد که اگر نمره(آماره بدست آمده) به بخش سطح معنی داری تعلق دارد از توزیعی شناخته شده آمده است و صحیح است که فرض صفر را بپذیریم.
ما باید تصویر روشنی از آنچه که مستلزم “قبول فرض صفر” است داشته باشیم. در حالت کلی “قبول” بدین معنی است که تفاوت معنی داری در آزمایش نیافته ایم. در حقیقت بعضی از نویسندگان ( کاهن، 1988، صفحه 16، همچنین ویلکینسون و نیروی کار در استنباط آماری، 1999) دلایلی آورده اند که گفتن اینکه فرض صفر پذیرفته می شود اشتباه است، بلکه همیشه باید بگوییم “فرض صفر را نمی توان رد کرد” زیرا بیان موقعیت به این صورت دقیق تر است و در واقع می گوییم دلیل کافی جهت رد فرض صفر نیافته ایم. در این حالت به طور یقین نشان نداده ایم که فرض صفر صحیح است. می توان ادعا کرد که دلیلی برای گفتن اینکه فرض درست است وجود ندارد، و ميان اين دو جمله تفاوت ظريفي وجود دارد. مجدداً ميگوئيم اگر ما در حفاري خود در جزيره گنج، گنجي نيابيم اين بدان معنا نيست كه در هيچ جايي اين جزيره گنج وجود ندارد. وقتيكه فرض صفر را ميپذيريم فقط ميگوئيم كه تفاوت به اندازه كافي بزرگ نيافتهايم تا احتمال بوجود آمدن اختلاف بوسيله شانس را رد كنيم. احتمال اختلافي ناشي از شانس در توزيع آنقدر براي ما بزرگ است كه نميتوانيم اختلاف حقیقی در توزيعها را ادعا كنيم. اگر ما گنجي نيافتيم دو احتمال ممكن است: اول در آنجا اصلاً گنجي وجود ندارد يا دوم در آنجا گنج وجود دارد ولي ما هنوز آنرا نيافتهايم. به صورت مشابه اگر ما يك تفاوت معنادار در ضمن آزمون فرض نيافتيم. ، ممكن است واقعاً تفاوتي در توزيعها وجود نداشته باشد يا آنكه تفاوتي وجود دارد ولي ما آن را از دست دادهايم. در حالت اول همه چيز خوب است ما تفاوتي نيافتيم در حاليكه واقعاً تفاوتي هم وجود ندارد كه بيابيم. در حالت دوم ما مرتكب خطاي نوع دوم شدهايم. ما توسط آزمونهایمان تفاوتی در توزیع ها نیافته ایم در حالیکه تفاوتی واقعی برای یافتن وجود داشت.
اگر يك نمره زير سطح معنی داری قرار بگيرد آنگاه ما فرض صفر را پذيرفته كه اين نمره از توزيع شناخته شده آمده است. اگر چه در اينجا اين ريسك وجود دارد كه نمره از توزيع ناشناخته آمده باشد (زيرا بخشي از توزيع ناشناخته زير سطح معنی داری است).



در اينجا مشكلي وجود دارد كه گاهي اوقات در تحليلهاي آماري از آن چشمپوشي ميشود. ما نميخواهيم آزموني كه ضعيف است انجام دهيم چون احتمال این كه تفاوت واقعی در توزيعها باشد وجود ندارد. ممكن است ما آزمايشي برجسته فقط براي عدم موفقيت دريافتن يك نتيجه معنادار بخاطر قدرت كم آزمون آماريمان ساخته باشيم. خوشبختانه توان بصورت فزآيندهاي موضوع مهمي در تحليلهاي آماري در بخش اخير قرن بيستم، بويژه بخاطر كارهاي (چاكوب كوهن، 1988) شده است. او ادعا كرده است كه انجام بيشتر تحقيقها بدون ملاحظه توان در مرحله طراحي، موجب آسيب رساندن به پروسه تحقيق شدهاند. نتيجه كار كوهن آن شد كه اكنون به محققين بيشتري قدرت را مراحل ابتدايي طراحي تحقيقشان مورد ملاحظه قرار ميدهند.
توان يك آزمون
وقتي تحقيق را آغاز ميكنيم ميخواهيم كه شانس خوبي براي يافتن يك اثر، اگر واقعاً يكي براي يافتن وجود داشته باشد، داشته باشيم. در مثال جستجوي گنج، كمك خوبي خواهد بود اگر بدانيم كه كار را براي يك دستگاه حفاري شروع ميكنيم اما هنوز مواردي زياد وجود دارد كه محققين با ابزارهاي آماري آغاز به كار ميكنند كه در حد همان تسلط و بيلچه كودكان هستند واضح بگوئيم ما يك آزمون توانمند ميخواهيم اما چگونه ميتوانيم آنرا انجام دهيم .





براي اينكه توان آزمون خود را در مرحله طراحي (مراحل اولیه) بدست بياوريم لازم است كه اندازه اثري را كه روي آن تحقيق ميكنيم بدانيم. ممكن است شما فكر كنيد كه: چگونه من اندازه اثر را پيش از انجام دادن تحقيق بدانم؟ يك منبع اطلاعاتي براي اين كار مطالعات پيشين است. مثلاً اگر ما سرعت تشخيص انواع مختلفي از لغات را آزمايش ميكنيم، ميدانيم به نوشتههايی در مورد اين موضوع نظر افكنده تا ببينيم در تحقيق هاي مرتبط افراد ديگر چه يافتهاند. ميتوانيم اين مطالعات را براي بدست آوردن برآوردی از اندازه اثري كه به دنبال آن هستيم به كار ببريم. اگر نوشتههاي كمي در اين مورد موجود باشد. ، چون شما روي يك عرصه جديد تحقيق ميكنيد. ، آنگاه يك تحقيق اكتشافي (مقدماتي) ممكن است ارزش انجام دادن را پيدا كند تا به شما احساسي از نتايجي كه ممكن است حاصل شود را بدست آوريد.
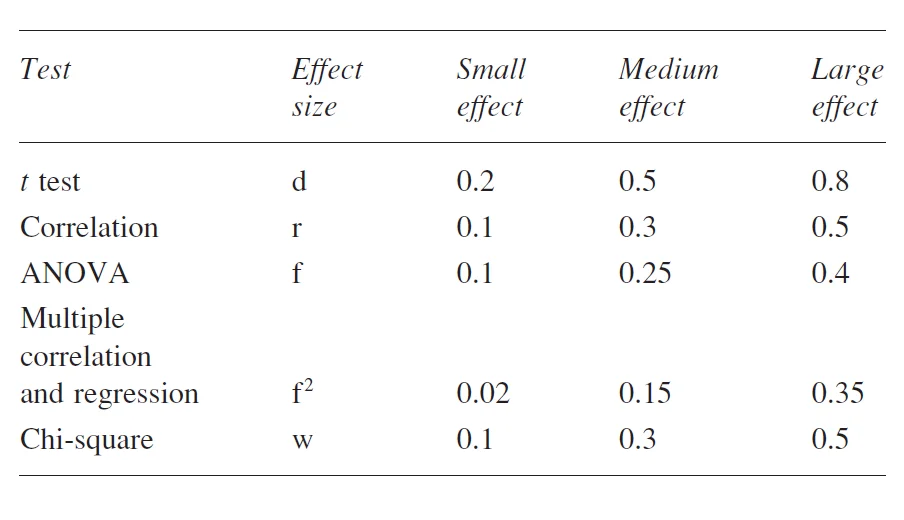
كوهن (1988) به عنوان راهنماي مفيد براي ارزيابي میزان اختلاف پيشبيني شده ، اثرات كوچك (2/0= d)، متوسط (5/0= d) و بزرگ (8/0=d) را از هم جدا كرد. او پيشنهاد كرد علاوه بر تلاش براي بدست آوردن يك اندازه اثر خاص بوسيله برآورد ميانگينها و انحراف استانداردها، ميتوان توجه نمود كه كجا انتظار يك اثر كوچك، متوسط، يا بزرگ را داريم. او ادعا كرد، براي بخشهای جدید از تحقیق اثرات اغلب كوچك هستند بخشي از آن به اين دليل است كه ابزارهاي اندازهگيري پيشرفتهاي ساخته نشده يا كنترل تجربي كه به انحراف استاندارد نسبتاً بزرگي منجر شود وجود ندارد. بنابراين اگر اعتقاد داشته باشيم كه اثري كه به دنبال آن هستيم كوچك است آنگه بطور معقول ميتوان اندازه اثر 2/0 را بپذيريم. كوهن پيشنهاد ميكند كه اثر متوسط با چشم غيرمسلح قابل رويت است (كوهن 1988 ص 26) به اين معنا كه ما از يك تفاوت آگاهيم همانند تفاوت ميان يك اپراتور دستگاه با تجربه و تازه كار چون خيلي واضح است اما ما ميخواهيم جزئيات آن را بيازمائيم. در چنين حالاتي ميتوانيم اندازه اثر متوسط حدود 5/0 را بپذيريم. در نهايت اثر بزرگي وجود دارند كه به صورت چشمگيري واضحند يا به صورت محسوسی قابل دركند آنگونه كه كوهن (27ص 988) ميگويد كه آن را بعنوان مثال خود تفاوت قد بين دختران 13 و 18 ساله به كار ميبرد. اگر باور داریم كه اثری كه به دنبال آن ميگرديم بزرگ است كوهن پيشنهاد ميكند كه اندازه اثر 8/0 را انتخاب كنيم.
در مثالها، نيازي نيست كه اندازه اثر را برآورد کنیم زيرا ميانگين و انحراف استاندارد جمعيت را اعلام نیاز کرده ایم كه به طور معمول آنها را نداريم. جالب است بدانيد در حيطه اصطلاحات كوهن ما يك پيشبيني اثر از متوسط تا بزرگ داريم چون d که بين 5/0 تا 8/0 تغییر می کند.
تأثيريگذاري اندازه اثر
ممكن است وسوسه شويد كه ادعا كنيد كه هرگز نميتوانيد اندازه اثر را تغيير دهيد زيرا مطمئناً یک اندازه اثر کوچک یک اثر كوچك است و قابل تغییر نیست. اما اگر براي لحظهاي توجه كنيم كه منظور ما از اندازه اثر چيست آنگاه ميتوانيم ببينيم كه چگونه ميتوان بر روي آن تأثير گذاشت. اندازه اثر بزرگ دلالت بر يك همپوشاني كوچك توزيعها دارد در حاليكه اندازه اثر كوچك دال بر همپوشاني بزرگ ميان توزيعها است. آنچه نياز است كه انجام دهيم تا توان آزمون و اندازه اثر را افزايش دهيم افزايش تفاوت ميانگينهاي توزيعها يا كاهش انحراف استاندارد آنها است.
يك راه مهم براي كاهش همپوشاني ميان توزيعها آن است كه تحقيق خودرا به خوبي طراحي كنيد. بسيار مهم است كه توجه كنيم يك طراحي خوب مستلزم چه چیزی است،این مسئله اساساً چيزي است كه باعث كاهش خطاها يا تغييرپذيري تصادفي در تحقيق شده و دقت اندازهگيري متغيرهاي تحت مطالعه را به حداكثر ميرساند.
هر چه بيشتر بتوانيد تغييرپذيري تصادفي در تحقيق را (با كنترلهاي صحيح در طراحي و روش کار) كاهش دهيد، اندازه اثر بزرگتر خواهد بود. تصور كنيد ما را در حال آزمودن تشخيص چهره هستيم. ممكن است تحقيق را در يك محيط طبيعي مثل فرودگاه انجام دهيم. یا ممکن است استفاده از صفحه نمایش کامپیوترهایی با زمانبندی دقیق و پاسخهای صفحه کلید در یک محیط آرام و به دور از هر گونه حواس پرتی را ترجیح دهیم تا بتوانیم تغییر پذیری تصادفی در مطالعه را کاهش دهیم.
حساسيت ابزارهاي اندازهگيري ميتواند به صورت سرنوشت سازي بر توان يك آزمون موثر باشد. اگر درباره شادماني افراد تحقيق ميكنيم ممکن است به جای اینکه از خود افراد درباره خوشحال بودن یا نبودن آنها سوال بپرسیم تمایل به استفاده از یک پرسشنامه بسیار پیچیده را داشته باشیم. به صورت مشابه اگر اثر ظريفي همچون سرعت خواندن يك متن متحرك را آزمون ميكنيم بايد از يك زمان سنج بسيار دقيق تا يك كرنومتر معمولي استفاده كنيم. علت آن است كه خطاي روشن و خاموش كردن كرنومتر ممكن است يكي دو ثانيه باشد كه ميتواند پدیده ای را كه فقط چند هزارم ثانیه طول می کشد در خود محو کند و اثر آن را نشان ندهد . اگر بتوانيم دقت زمان اندازهگيري را افزايش دهيم آنگاه احتمال بیشتری برای یافتن اثر (البته اگر وجود داشته باشد) وجود دارد.
اندازه نمونه
وقتيكه كه نمونهاي را به عنوان نماینده ای از جمعیت مورد مطالعه قرار ميدهيم توزيعهاي نمونهگيري را براي نمايش توزيعهاي شناخته شده و ناشناخته به كار ميبريم. انحراف استاندارد توزيع نمونهگيري یعنی همان خطاي استاندارد ميانگين به همان اندازه كه نمونه بزرگتر ميشود كوچكتر ميگردد. اين بدان دليل است كه خطاي استاندارد براي مبناي انحراف استاندارد جمعيت و اندازه نمونه، است.

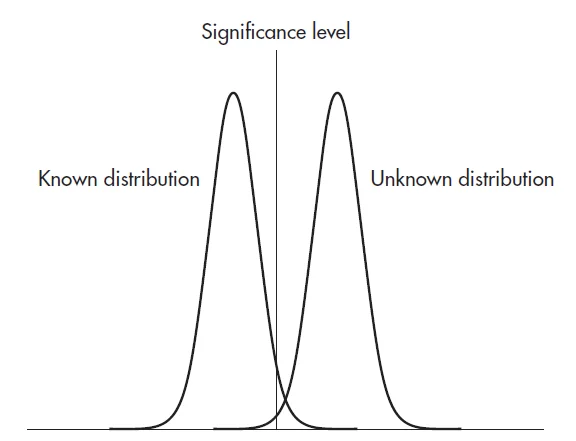
تصویر 9.2- اثر افزایش نمونه میزان همپوشانی توزیع ها
ميتوان تأثير اندازه نمونه در آمار را با مثال زير نمايش داد. فرض كنيد كه جمعيت شناخته شدهاي توزيع نرمالي با ميانگين 100 و انحراف استاندارد 15 داشته باشد. فرض ميكنيم جمعيت ناشناخته نيز واقعا متفاوت بوده و ميانگين آن 110 است. البته در اين حالت جمعيت ديگر ناشناخته نيست بنابراين ما نيازي به انجام هيچ كار آماري نداريم زيرا آنچه را كه ميخواهيم ميدانيم اما اين فقط براي نشان دادن بعضی مفاهیم است.
ابتدا بايد موقعيت را وقتي كه نمونه 10 تايي به كار گرفته شده است بيازمائيم. ميانگين توزيع نمونهگيري دو جمعيت 100 و 110 است ولي انحراف استاندارد آنها، در واقع خطاي استاندارد برابر خواهد بود با:


انتخاب اندازه نمونه در آزمون آماري
يك تصميم مهم براي يك محقق، تصميم گرفتن درباره تعداد شركتكنندگان در تحقيق است اين جايي است كه كار كوهن به صورت خاص سودمند است. همانطور كه در بالا متذكر شديم توان آزمون بستگي به سطح معنی داری ، اندازه اثر و اندازه نمونه دارد. ما ميتوانيم اين رابطه را برگردانيم و ببينيم كه اندازه نمونه تابعي از سطح معنی داری ، توان آزمون و اندازه اثر است.
محققي درباره صفحه نمايشهاي مختلفي براي صفحه نمايش تجهيزات پزشكي بيمارستانهاي تحقيق ميكند. دو نوع از صفحه نمايشها بايد در آزمايشگاه مقايسه شوند تا ببينيم كه استفاده از كداميك منجر به خطاي كمتري در خواندن ميشود. محقق ميخواهد بداند كه چه تعداد شركت كننده در آزمايش بايد استفاده كند. او تصميمگير می گیرد كه از سطح معنی داری 05/0= P براي يك آزمون دو طرفه استفاده كند. توان مورد نياز براي آزمون 8/0 در نظر گرفته شد و فرض بر آن قرار گرفت كه اندازه اثر متوسط بوده بنابراین 5/0 براي اندازه اثر تعيين شد. يك آزمون tبايد روي دادههاي خطا انجام شود.
آيا ميتوانيم محاسباتي همچون بخش پيشين براي يافتن پاسخ انجام دهيم، ؟ جواب هم بله و هم خير است. بله چون می توانیم محاسباتي براي بدست آوردن تعداد شركتكنندگان انجام دهيم و نه چون اين مورد مثل مورد بخش پيشين نيست زيرا در آنجا دادههاي جمعيت را داشتيم و در اينجا نداريم. وقتيكه دو نمونه را مقايسه ميكنيم توزيع tرا بعنوان توزيع مناسب براي تحليل خود به كار ميبريم. اما در اينجا يك پيچيدگي وجود دارد زيرا توزيع t كه ما معمولاً براي محاسبه يك آزمون t به كار ميبريم براساس نمونههايي است كه از يك توزيع آمدهاند يعني وقتيكه نمونهها از يك جمعيت باشند.




مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




