آنالیز واریانس یک عاملی برای داده های رتبه ای – بخش 2
29 آذر 1400
دقیقه
در مقاله قبلی به بخش دوم آنالیز واریانس یک عاملی برای داده های رتبه ای در نمونه های وابسته پرداختیم. در این فصل به آموزش بخش دوم آنالیز واریانس یک عاملی برای داده های رتبه ای، در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم.

آخرین بهروزرسانی: 24 دی 1401
در مقاله قبلی به بخش دوم آنالیز واریانس یک عاملی برای داده های رتبه ای در نمونه های وابسته پرداختیم. در این فصل به آموزش بخش دوم آنالیز واریانس یک عاملی برای داده های رتبه ای، در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم.
آنالیز واریانس یک عاملی برای داده های رتبه ای

مثال کاربردی
به نظر گروهي 18 نفره توافق اينكه جهت راحتي شركت در امتحان كدام يك از روش هاي قرص آرامبخش، هيپنوتيزم و يا ورزش تأثيرگذار تر است امري سخت بود.
پس از يك هفته بكارگيري روش هاي ذكر شده از شركت كنندگان خواسته شد تا به ميزان تواناييشان در رسيدن به آرامش امتيازي در مقياس 50 نقطه بدهند (كه بازه از صفر شروع شده و اين مقدار بدترين حالت ممكن بوده، 25 به معناي عدم تغيير، تا 50 كه نشاندهنده ي بهتر بودن نسبت به حالات قبلي است).
شش نفر از افراد ذكر شده متعهد استفاده از قرص آرامبخش شدند، پنج نفر روش هيپنوتيزم را عملي كردند و هفت نفر به تمرين هاي ورزشي پرداختند. آيا اثر روش آرامش تأثيري روي امتيازهاي داده شده توسط آنها دارد؟
داده ها به همراه رتبه هايشان در جدول زير نمايش داده شده اند.
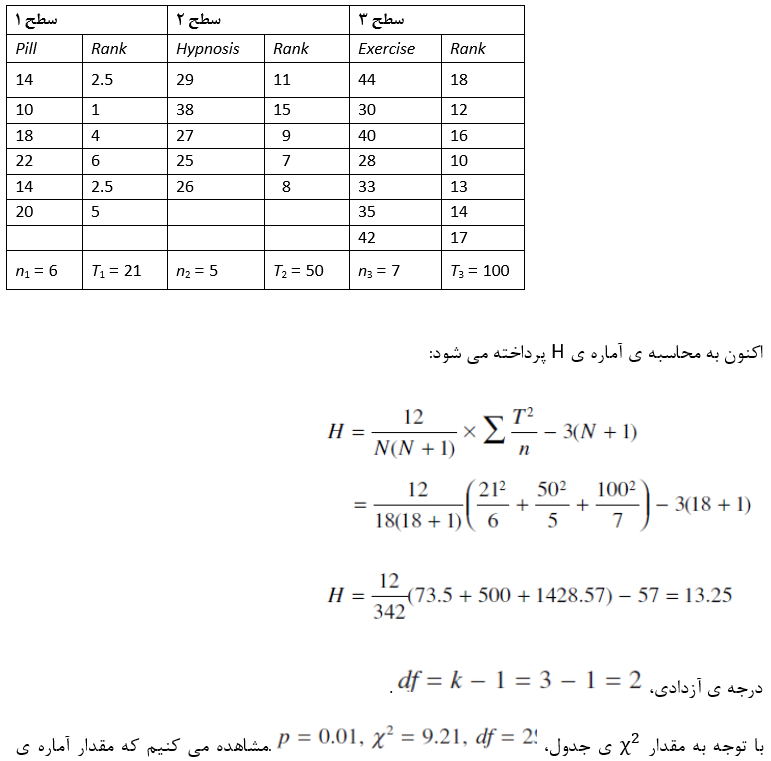
محاسبه شده برابر با 13.25 و از مقدار جدول بزرگتر است (جدول A.7 ضميمه). بنابراين نتيجه مي گيريم كه (در سطح p = 0.01) اختلاف معني داري ميان ميزان آرامش با امتياز داده شده توسط شركت كننده وجود دارد.
مقايسات چندگانه پست هاك در آزمون كروسيكال-واليس
بعد از معني دار شدن آزمون كروسيكال-واليس به روشي مشابه روش توكي مي توان مقايسات چندگانه پست هاك را انجام داد. اختلاف معني دار قابل اعتماد Tukey’s honestly significant difference روش توكي=انحراف استاندارد q×، كه q آماره ي دامنه ی استيودنت شده (Studentized range statistic) است.
در ادامه ي آزمون كروسيكال-واليس جهت مقايسه ي دوتايي نمونه ها به جاي مقايسه ي ميانگين نمونه ها با استفاده از آزمون نمني (Nemenyi test) رتبه هاي كل نمونه ها را مقايسه مي كنيم. خطاي استاندارد (SE) به طريق زير محاسبه مي شود:
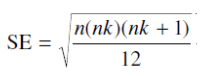
كه k تعداد سطوح و n تعداد نمرات هر سطح است. با داشتن سطح معني داري (معمولا 0.05) و تعداد نمونه ي k مقدار q را از جدول A.4 بدست مي آوريم كه در اين حالت با درجه ي آزادي بينهايت ∞ مواجه هستيم. در صورتيكه تفاوت يك زوج از رتبه هاي كل ( به عنوان مثال T1 و T2) از مقدار q x SE بزرگتر باشد در سطح معني داري انتخاب شده اختلاف معني داري ميان دو ميانگين (مترجم: دو سطح مورد نظر) وجود دارد.
مشكل آزمون نمني نيازمند به يكسان بودن اندازه ي كليه نمونه هاست (n). با اندازه نمونه هاي نابرابر از آزمون دان (Dunn ) با مقدار SE زير استفاده مي شود.
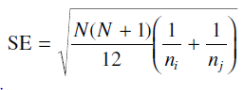
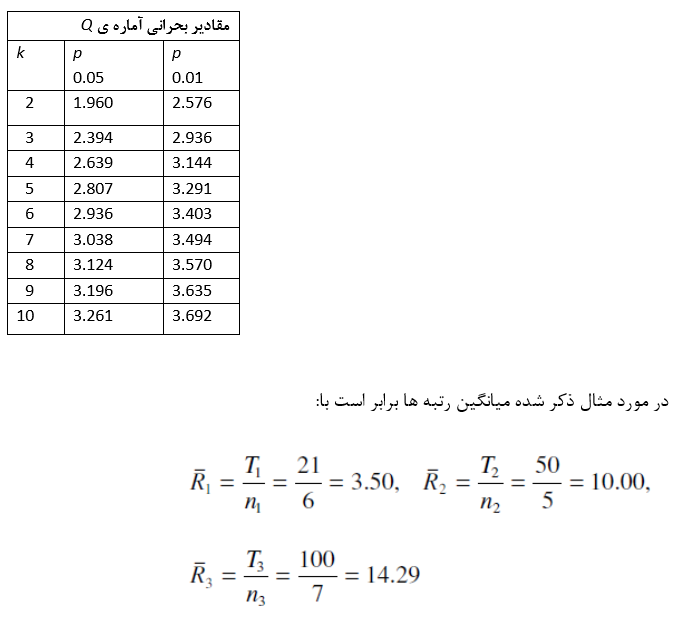
كه در آن ni و nj اندازه ي نمونه هاي دو سطح هستند. (فوت نات 15) براي محاسبه ميانگين رتبه مي بايست رتبه ي كل مورد نظر را با اندازه ي سطح خودش مقايسه كرد (به عنوان مثال در سطح 1 ميانگين رتبه برابر با (T1/n1) خواهد بود. جهت معني داري بايد ميانگين رتبه ها از مقدار Q X SE بزرگتر باشد. Q آماره ي تفاوت ها در ميانگين رتبه ها است و مقادير آن براي مقادير متفاوت k در سطوح معني داري 0.05 و 0.01 در جدول مربوطه آمده است.

آزمون فرید من (در نمونه های وابسته)
آزمون فرید من، آزمونی ناپارامتری بوده و زمانی که نتوان فرضیات مورد نیاز آزمون های پارامتری آنالیز واریانس با اندازه گیری های مکرر برقرار کرد به کار می رود. در این آزمون نیز تحلیل ها براساس رتبه ها انجام می شوند. از آنجاییکه که نمرات به صورت اندازه گیری های تکرار شده ای هستند، جهت رتبه دادن در هر آزمودنی نمرات كليه سطوح را با هم در نظر گرفته و رتبه می دهیم.
در مثالی که در ادامه خواهد آمده از شش نفر از پرسنل یک اداره درخواست می شود که در مقیاس 10-0 بر حسب تصویر ذهنی حرفه ای به رنگ هایی جهت لباسی برای کسب و کار امتیاز بدهند. سه لباس که سه سطح را تشکیل می دهند با رنگهای: قهوه ای، مشکی وآبی انتخاب شدند.
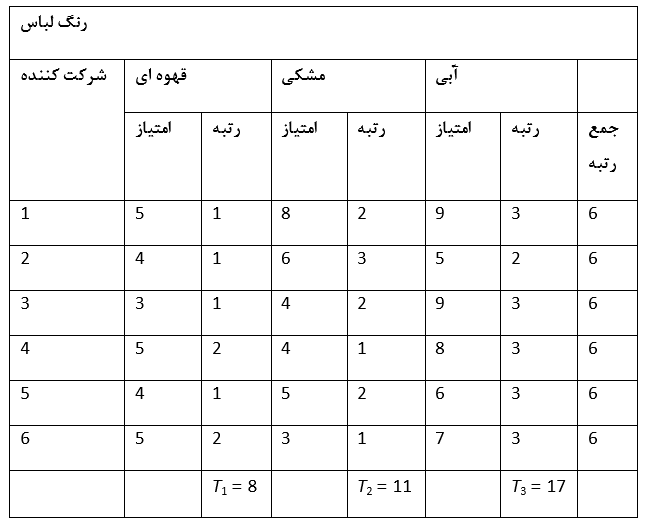
در صورتیکه تفاوت معنی داری میان نمونه ها وجود نداشته باشد انتظار می رود که رتبه ها به صورت یکنواخت در سطوح پراکنده شده باشند. اما اگر متغیر وابسته اثری معنی دار داشته باشد انتظار داریم که رتبه های مشابه به صورت خوشه هایی در سطحی خاص قرار گیرند.
در مورد مثال ذکر شده بیشتر رتبه های 1 در سطح قهوه ای هستند، بیشتر رتبه های 2 به مشکی اختصاص داشته و اکثریت رتبه های 3 در سطح آبی قرار گرفته اند؛ بنابراین انتظار می رود که آماره ای که محاسبه می کنیم اختلاف معنی داری را بین سطوح نشان دهد. در مورد آنالیز

این فرمول ها تاحدودی با آنچه که در فصل 16 مشاهده کردیم متفاوتند، زیرا در آنجا رتبه ها را درون هر آزمودنی داده و کلیه نمرات موجود در آزمایش با هم در نظر گرفته نمی شدند. اکنون می توان فرمول های مربوط به آنالیز واریانس را با فرمول های رتبه ها تعویض کرد.


مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




