استفاده از ابزار Solver برای امتیازدهی به تیمهای ورزشی
03 خرداد 1401
دقیقه
بسیاری از ما مسابقات بسکتبال، فوتبال، هاکی و یا بیسبال را دنبال میکنیم. شرط بندها برای همه این بازیها در تمام رشتههای ورزشی صفحات پیشبینی امتیاز تشکیل میدهند.

آخرین بهروزرسانی: 27 دی 1401
در سری مقاله های آموزش اکسل، در فصل گذشته به استفاده از ابزار Solver برای برنامهریزی مالی پرداختیم، در این مقاله “استفاده از ابزار Solver برای امتیازدهی به تیمهای ورزشی” را مورد بررسی قرار میدهیم.
پیشبینی امتیازهای لیگ ملی فوتبال با ابزار Solver
آیا میتوان از ابزار Solver برای پیشبینی امتیازهای لیگ ملی فوتبال[1] استفاده کرد؟
بسیاری از ما مسابقات بسکتبال، فوتبال، هاکی و یا بیسبال را دنبال میکنیم. شرط بندها برای همه این بازیها در تمام رشتههای ورزشی صفحات پیشبینی امتیاز تشکیل میدهند. مثلاً بهترین حدس دلالان شرطبندی آن بود که تیم کارولینا پنترز جام سوپرباول سال 2016 را با پنج امتیاز برنده میشود. اما در عوض تیم دنور برونکوز بود که برنده این جام شد. در این فصل میآموزیم که ابزار Solver چگونه میتواند به شکلی صحیح قدرت و تواناییهای نسبی تیمهای لیگ ملی فوتبال را تخمین زند.
میتوان با استفاده از مدل Solver سادهای بر اساس امتیازهای سال 2017 صفحات پیشبینی نتایج عاقلانهای برای بازیها ایجاد کنید (شامل تمام بازیها بهجز بازی سوپر باول سال 2018). این تمرین که در تصویر 1-35 نشاندادهشده، در فایل Nfl2017.xlsx است. بهسادگی میتوانیم از امتیازهای هر بازی فصل 2017 لیگ ملی فوتبال بهعنوان دادههای ورودی استفاده کنیم. سلولهای متغیر برای مدل Solver امتیاز هر تیم و میزان امتیاز تیمهای خانگی است. مثلاً اگر تیم ایندیاناپولیس کولتز رتبه 5+ و نیویورک جتز رتبه 7+ داشته باشد بنابراین تیم جتز دو امتیاز بهتر از تیم کولتز است.
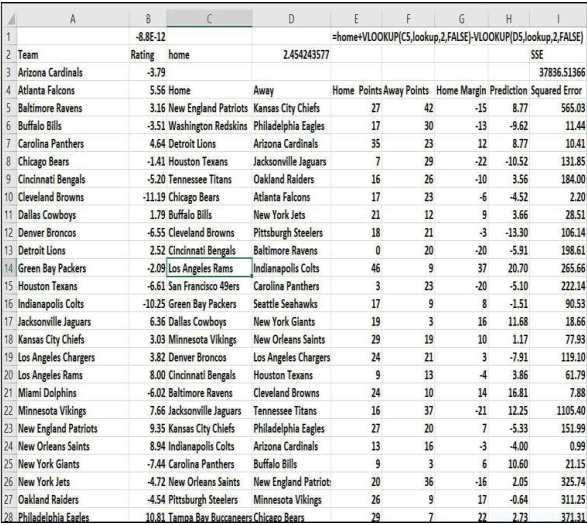
تصویر 1-35 دادههای امتیاز لیگ ملی فوتبال تیمها که در ابزار Solver از آنها استفاده خواهیم کرد.
باتوجهبه امتیاز میزبانی، تیمهای فوتبال حرفهای و دانشگاهی هم مثل تیمهای بسکتبال حرفهای معمولاً در بیشتر سال به طور متوسط با سه امتیاز برنده میشوند (درحالیکه تیمهای بسکتبال دانشگاهی به طور متوسط با پنج امتیاز برنده میشوند). هرچند در مدل ما امتیاز میزبانی را بهعنوان سلول متغیر قرار میدهیم و ابزار Solver را مجبور میکنیم تا آن را تخمین بزند. میتوان خروجی یک بازی لیگ ملی فوتبال را با معادله زیر (که آن را معادله 1 مینامیم) به تعداد امتیازهایی که تیم میزبان از تیم مهمان پیشی گرفته تعیین کرده و نتیجه بازی را پیشبینی کنید.
(امتیازهای پیشبینی شده که بر اساس آن تیم میزبان از تیم مهمان پیشی گرفته)=(امتیاز میزبانی)+(رتبه تیم میزبان)- (رتبه تیم مهمان)
مثلاً اگر امتیاز میزبانی برابر با 3 امتیاز باشد، هنگامی که تیم کولتز میزبان تیم جتز میشود، تیم کولتز یک امتیاز جلو میافتد (7-5+3) و اگر تیم جتز میزبان تیم کولتز شود تیم جتز پنج امتیاز جلو میافتد. (5-7+3(
کدام سلول هدف رتبهبندی قابل اعتمادی ارائه میدهد؟ هدف آن است که مجموعهای از مقادیر برای رتبهبندی تیمی و امتیازات و مزایای میزبانی پیدا کنیم که بهترین نتایج را برای کل بازیها ارائه دهد. خلاصه بگوییم، میخواهیم پیشبینی نتایج هر بازی تاحدامکان نزدیک به نتایج هر تیم باشد.
این نشان میدهد که قصد داریم سرجمع تمام بازیها (نتایج واقعی)- (نتایج پیشبینی شده) را به حداقل برسانیم. هرچند مشکل استفاده کردن از این هدف آن است که خطاهای پیشبینی مثبت و منفی تأثیرات یکدیگر را کم میکنند. مثلاً اگر امتیازات میزبانی را در یک بازی 50 امتیاز بیشتر و در بازی دیگری 50 امتیاز کمتر پیشبینی کرده باشید سلول هدف عدد صفر را نشان میدهد که نمایشگر دقت کامل است درحالیکه درواقع در هر بازی 50 امتیاز کم دارید. میتوانید این مشکل را با کمکردن جمع تمامی بازیها با استفاده از فرمول ] (نتیجه واقعی بازی)- (نتیجه پیشبینی شده)[2 حل کنید، اکنون خطاهای مثبت و منفی یکدیگر را خنثی نخواهند کرد.
اکنون بیایید ببینیم چگونه با استفاده از امتیازهای فصل معمولی سال 2017 رتبهبندی مناسبی برای تیمهای لیگ ملی فوتبال انجام دهیم. میتوانید دادههای مربوط به این مسئله را در فایل Nfl2017.xlsx که در تصویر 1-35 نمایشدادهشده مشاهده کنید.
برای شروع مقدار مربوط به مزایای میزبانی را در سلول D2 قرار میدهیم و محدوده سلول را home (میزبان) می نامیم. همچنین در محدوده B3:B34 مقادیر آزمایشی (هر عددی میتواند قرار داده شود) برای رتبهبندی هر تیم قرار میدهیم.
حالا از ردیف 6، ستون C و D که حاوی تیمهای میزبان و مهمان هر بازی هستند شروع میکنیم. مثلاً اولین بازی (که در ردیف 5 فهرست شده) متعلق به کانزاسسیتی است که در نیوانگلند بازی میکند. ستون E حاوی امتیاز تیم میزبان و ستون F حاوی امتیاز تیم مهمان است. همانطور که میبینید تیم پاتریوتس با نتیجه 42 به 27 بازی را به تیم شیفز باخته است. حالا میتوانم نتایج کلی هر تیم (تعداد امتیازهایی که تیمهای میزبان با آن تیمهای مهمان را شکست خواهند داد) را با واردکردن فرمول =E5-F5 در سلول G5 محاسبه کنم. با قراردادن نشانگر ماوس در بخش پایینی سمت راست سلول و دو بار کلیک کردن با دکمه سمت چپ ماوس میتوانید این فرمول را تا آخر بازیهای لیست شده تا ردیف 270 کپی کنید. (روشی آسان برای انتخاب تمامی دادهها فشار دادن کلیدهای Ctrl+ shift و کلید جهت روبه پایین است. این ترکیب از کلیدها شما را به آخرین ردیف حاوی داده که در این مورد ردیف 270 است میبرد)
در ستون H از معادله 1 استفاده میکنیم تا نتیجه هر بازی را پیشبینی کنیم. پیشبینی برای اولین بازی در سلول H5 به شکل زیر محاسبه شده است:
=home+VLOOKUP(C5,lookup,2,FALSE)-VLOOKUP(D5,lookup,2,FALSE)
این فرمول با اضافهکردن امتیاز بازی خانگی به رتبهبندی تیم خانگی و بعد کمکردن رتبهبندی تیم مهمان از آن برای بازی اول پیشبینی ایجاد میکند. شرط VLOOKUP(C5,lookup,2,FALSE)رتبهبندی تیم میزبان را پیدا میکند و VLOOKUP(D5,,lookup,2,FALSE) رتبهبندی تیم میهمان را پیدا میکند (برای اطلاعات بیشتر درباره استفاده از توابع Lookup فصل 3 یعنی توابع Lookup را مطالعه کنید) در ستون I خطای میانگین مربعات (actual score–predicted score)2 هر بازی را محاسبه کردهایم. خطای میانگین مربعات برای اولین بازی در سلول 16 با فرمول =(G5-H5)^ 2 محاسبه شده است. پس از انتخاب محدوده سلول C5:I5 میتوانید با دو بار کلیک فرمول را تا ردیف 270 کپی کنید.
اکنون سلول هدف را در سال I3 با جمع زدن تمام خطای میانگین مربعات با فرمول =SUM(I5:I270) محاسبه میکنیم. میتوان با تایپ =SUM و سپس انتخاب اولین سلول در محدودهای که میخواهید جمع بزنید فرمولی برای محاسبه ستون بسیار بزرگی از اعداد وارد کرد. در ادامه کلیدهای Ctrl+Shift و کلید جهت پایین را فشار میدهیم تا محدوده سلولی را تا ردیف پایانی در ستون انتخاب کنیم و سپس پرانتز را میبندیم.
بسیار مناسبتر است که رتبهبندی میانگین تیم برابر با صفر باشد. تیمی با رتبهبندی مثبت بهتر از متوسط است و تیمی با رتبهبندی منفی بدتر از متوسط است. در اینجا رتبهبندی متوسط تیم را در سلول B1 با فرمول =AVERAGE(B3:B34) محاسبه میکنیم.
حالا میتوانیم کادر محاورهای Solver Parameters را همانطور که در تصویر 2-35 نشاندادهشده پر کنیم.
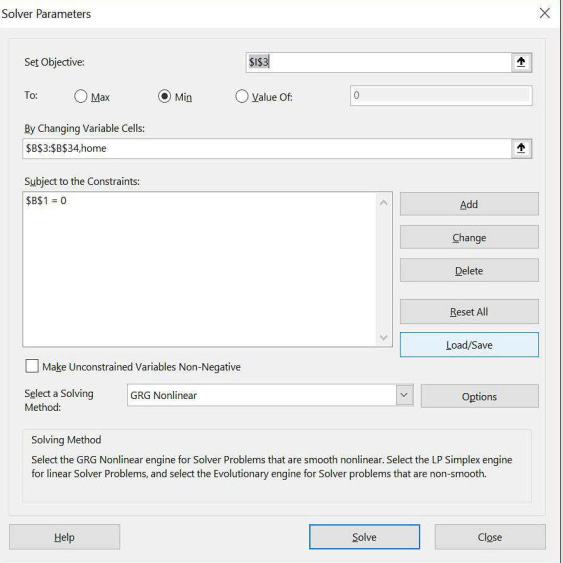
تصویر 2-35 کادر محاورهای Solver Parameters که برای رتبهبندی NFL تنظیم شده است.
ما با تغییر رتبهبندی هر تیم (در محدوده B3:B34 که آن را Rating یا رتبهبندی نامیدیم) و امتیاز میزبانی (سلول D2)، جمع خطاهای میانگین مربعات در تمامی بازیها را به حداقل رساندیم. محدودیت B1=0 به ما اطمینان میدهد که میانگین رتبهبندی تیم صفر است. توجه کنید که در اینجا گزینه Changing Cells Nonnegative را فعال نکردهایم چرا که برخی از تیمها میبایست رتبهبندیهای منفی داشته باشند تا در زیر حد میانگین قرار گیرند.
تصویر 1-35 نتیجه رتبهبندیها و امتیاز میزبان را که پس از اجرای ابزار Solver بهدستآمده را نشان میدهد. میتوانید ببینید که تیم میزبان 2.45 امتیاز بر تیم مهمان برتری دارد. 20 تیم دارای رتبههای برتر (که به مرحله سوپرباول یا جام نهایی میروند) در تصویر 3-35 نشاندادهشدهاند. بهخاطر داشته باشید که رتبهبندیهای لیست شده در محدوده سلول B3:B32 توسط ابزار Solver محاسبه شدهاند. شما میتوانید در فایل الگو کار را با هریک از عددها در این سلولها آغاز کنید و ابزار Solver بهترین رتبهبندی را برای شما پیدا خواهد کرد.
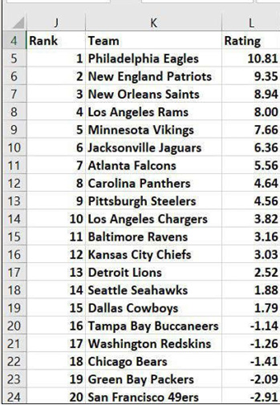
تصویر 3-35 تیمهای بالای رتبه 20 فصل 2017 لیگ ملی فوتبال
در مسابقات سوپرباول سال 2018، مسئولین شرطبندی تیم نیوانگلند را با هفت امتیاز بیشتر ترجیح دادند. مدل ما نیز پیروزی تیم نیوانگلند را پیشبینی کرد که هواداران رنجکشیده تیم ایگلز را (فیلم دفترچه امتیازات خوشبینانه را ببینید) از شادی به خلسه فروبرد.
چرا مدل ما یک مدل Solver خطی نیست؟
این یک مدل خطی نیست چرا که سلول هدف تمامی شروط شکل (رتبهبندی تیم میزبان+ امتیاز میزبانی – رتبهبندی تیم مهمان) 2 را باهم جمع میزند. بهخاطر داشته باشید برای آنکه مدل Solver خطی باشد، سلول هدف میبایست با جمع زدن تمامی شروط شکل (سلول متغیر)*(محدودیت) ایجاد شود.
در این مورد، رابطه موردنظر برقرار نیست؛ بنابراین مدل خطی حساب نمیشود. البته Solver در مورد هر مدل رتبهبندی ورزشی که در آن سلول هدف جمع خطاهای میانگین مربعات را کوچک میسازد دارای پاسخ صحیح است. توجه کنید که ما موتور غیرخطی GRG را انتخاب کردیم چون این مدل خطی نیست و دارای توابع غیر ریاضی ناهموار مثل گزارههای IF نمیباشد.
مسئلههای این فصل
فایلی به نام Nflox.xlsx(X=1,2,3,4) حاوی امتیازات هریک از بازیهای فصول عادی در لیگ ملی فوتبال سال 200X است. هر تیم را در هر فصل امتیاز دهید. در هر فصل، ترجیح میدهید کدامیک از تیمها به مرحله سوپرباول (جام نهایی) راه پیدا میکنند؟
برای فصل بازی سال 2004 روشی ابداع کنید که امتیاز واقعی هریک از تیمها را پیشبینی کند. اشاره: به هر تیم امتیازی تهاجمی و امتیازی دفاعی بدهید. کدام تیم بهترین امتیاز تهاجمی داشت؟ کدام تیم بهترین امتیاز دفاعی داشت؟
درست یا نادرست؟ تیم لیگ ملی فوتبال میتواند در هر بازی بازنده باشد و درعینحال تیم بالای متوسطی محسوب شود.
فایلی به نام Nba01-02.xlsx حاوی امتیازهای تمامی بازیهای NBA(انجمن ملی بسکتبال) در فصلهای بازی سالهای 2002-2001 میباشد. تیمها را رتبهبندی کنید.
فایلی به نام Nba02-03.xlsx حاوی امتیازهای تمامی بازیهای NBA(انجمن ملی بسکتبال) در هر فصل عادی بازی سالهای 2003-2002 میباشد. تیمها را رتبهبندی کنید.
فایلی به نام Worldball.xlsx حاوی امتیازهای بازیهای جام جهانی بسکتبال سال 2006 است. به این تیمها امتیاز دهید. سه تیم برتر کدامند؟
روش امتیازدهی تیمی ما برای ورزشهای فوتبال و بسکتبال مناسب است. اگر بخواهید این روش را در هاکی یا بیسبال اجرا کنیم چه مشکلاتی پیش میآید؟
فایلی به نام NflFL2012data.xlsx حاوی امتیازهای تمامی بازیهای فصل عادی سال 2012 لیگ ملی فوتبال است. تیمها را رتبهبندی کنید. با اینکه تیم کولتز دارای امتیاز 6-10 بود، رتبهبندی شما این تیم را زیر حد متوسط قرار داده است. میتوانید این ناهنجاری پیشآمده را توضیح دهید؟
[1] NFL




