آمار به زبان ساده – مقايسه های چندگانه
07 آبان 1400
دقیقه
در این مقاله به بررسی مقايسه های چندگانهی آزمون توكی Tukey (برای همه مقایسههای دوگانه) و آزمون شفه Scheffé (برای مقایسه های پیچیده) می پردازیم.

آخرین بهروزرسانی: 24 دی 1401
در این مقاله به بررسی مقايسه های چندگانهی آزمون توكی Tukey (برای همه مقایسههای دوگانه) و آزمون شفه Scheffé (برای مقایسه های پیچیده) می پردازیم. برای مطالعه بیشتر میتوانید به مقالات آمار به زبان ساده مراجعه نمایید.
وقتیكه بیشتر از دو گروه را در آنالیز واریانس مقایسه میكنیم مقدار معنادار F مشخص نمیكند كه اثر در كجاست، و فقط به صورت خیلی ساده بیان می کند که جایی بین سطوح اثری معنی دار وجود دارد. یك محقق 4 گروه از كودكان (6، 8، 10 و 12 ساله) را در یك آزمون رفتار اجتماعی مقایسه نمود. او یك مقدار F معنادار یافته و نتیجه گرفت كه نمرات این چهار سطح از یك توزیع نمیآیند. اما این نتیجهگیری حقیقتاً به محقق اطلاعاتی درباره آنكه كدام محدوده سنی تفاوت معناداری دارد را نشان نمیدهد.
اجازه دهید فرض كنیم كه میانگین آنها به ترتیب 10، 12، 18 و 23 (از 50) است. با این دادهها كه نسبت واریانس معناداری را در خود دارند محتمل به نظر میآید كه نمرات 6 سالهها به صورت معناداری از 12 سالهها متفاوت بوده زیرا این مقایسه بیشترین تفاوت در میانگین را نشان میدهد. آیا تفاوت بین 6 و 8 سالهها یا 8 ساله و 10 سالهها معنادار است؟ و همچنین درباره كمترین اختلاف بین 6 و8 سالهها؟ برای یافتن یك مقدار F معنادار، میبایستی دادهها را مورد وارسی قرار داد. راهی كه، به این سؤالات بتوانیم پاسخ دهیم آن است كه یك آزمون پست هاک انجام دهیم (post hoc این نام از لاتین گرفته شده و به معنای «بعد از این» است.)
اولین مرحله در تحلیل این است كه یك مقدار معنادار F در آنالیز واریانس بیابیم. تنها پس از آن است كه میتوانیم یك آزمون پست هاک انجام دهیم. این آزمونها، آزمونهای مقایسهای چندگانه نامیده میشوند زیرا به ما اجازه می دهند كه مقایسههای مختلفی بین سطوح انجام دهیم. در مثال بالا ما میخواهیم كه هر یك از چهار گروه را با دیگر گروهها مقایسه كرده تا نشان دهیم كه تفاوتهای معنادار در كجا هستند.
مشكل با مقایسههای چندگانه آن است كه هر چه مقایسههای بیشتری با همین دادهها انجام دهیم، ریسك ایجاد خطای نوع اول را بالاتر میبریم. در فصل 10 دیدیم كه این همان مشكلی است كه با انجام آزمونهای چندگانه t داشتیم یعنی وقتیكه شروع به انجام آزمونهای چندگانه بر روی دادهها میكردیم ریسك یافتن اختلافهای شانسی را افزایش می دادیم. راه حل آن است كه یك آزمون پست هاک كه این ریسك فزاینده را در نظر گرفته و آن را كنترل میكند انجام دهیم.
محدودهای از آزمونهای چندگانه وجود دارد. بعضی از آنها مشكل را به كلی نادیده میگیرند. آزمون كمترین تفاوت معنادار توجهی به تعداد مقایسههای انجام شده ندارد و ریسك خطای نوع اول در آن به راحتی پذیرفته شده است. دیگر آزمونها مثل آزمون نیومن – كیولز و دانكن تعداد مقایسههای انجام شده را در نظر گرفته و متناسب با آن مقادیر متفاوت را محاسبه میكنند. در محافظهكارانهترین حالت از این محدوده از آزمونها، آزمونهای توکی و شفه اجازه همه مقایسهها را می دهند، همچنانکه آزمون ریسك فزاینده خطای نوع اول را با كاهش سطح معنی داری مقایسههای جداگانه، اصلاح میكند.
آسان ترین و محافظهكارانهترین روش اعمال اصلاح بن فرونی را به سطح معنی داری است. برای مثال اگر آنالیز واریانس (ANOVA) با یک عامل اندازه گیری شده مستقل مقدار F معناداری را نشان دهد.، آنگاه میتوان آزمونهای t را به دنبال آن بر روی 6 جفت از سطوح با یك اصلاح بن فرونی برای درستكردن سطح معنی داری این آزمونها انجام داد. اصلاح بن فرونی (Bonferroni) ما را ملزم میكند كه سطح معنی داری را بر تعداد آزمونها تقسیم كنیم بنابراین در این حالت هر آزمون باید در مقابل سطح معنی داری 6/05/0=P (0083/0=P) ونه سطح معنی داری 05/0 انجام شود.
این مسئله بر توان آزمون تأثیر گذاشته و میتواند به عنوان محافظهكاری افراطی به دلیل كاهش توان باشد. من بدلایلی كه در زیر میآید میخواهم هر دوی آزمونهایی بسیار محافظهكارانه توکی و شفه را تشریح كنم. معمولاً وقتیكه ما یك نسبت واریانس معنادار آنالیز واریانس را مییابیم، میخواهیم كه همه حالات را برای یافتن تفاوتهای جالب (معناداری) مقایسه كنیم همانطور كه در آزمون رفتار اجتماعی بالا آمد. آزمونهای توكی و شفه به ما اجازه این كار را داده بدون اینكه بیش از حد نگران ریسك ایجاد خطای نوع اول باشیم. دیگر آنكه انجام آنها خصوصا آزمون توكی آسان است.
این واقعیت كه آنها مقادیر بحرانی بالایی برای معناداری تعیین میكنند، ما را به از دست دادن یافتههای معنادار بالقوه نمیكشاند زیرا ما یك معیار معناداری بسیار سختیگیرانه داریم. ممكن است زمانیكه این آزمونها را مورد استفاده قرار می دهیم بعضی تفاوتها را همانند وقتیكه آزمونهای دیگری را به كار میبریم معنادار ندانیم اما این مشكلی ایجاد نخواهد كرد اگر ما به یاد داشته باشیم كه قضاوت خود را به عنوان یك محقق به كار ببریم.
اگر تفاوتی وجود دارد كه در این آزمونها به حد كفایت معنادار بودن نرسیده است اما ما هنوز دلایلی برای باور اینكه تفاوتها مهم هستند داریم، آنگاه همانند دیگر حالاتی از این نوع، ما باید به قضاوت خود اطمینان كرده و آن را دنبال كنیم: یعنی آزمایشها را تكرار كنیم، عنوان های موضوعی بیشتری را به كار ببریم، طراحی حساستری را به كار ببریم و اساساً معیارهایی را برای بهبود آزمون خود به كار ببریم. اگر تفاوتی واقعی وجود داشته باشد حتی با یك آزمون توكی بتدریج ظاهر خواهد شد.
آمار تنها ابزاری برای كمك به ماست و جایگزین مهارت و هوش آزمایشكننده نخواهد شد. برای من هم پیش آمده است كه برای اطمینان از نتیجه تحلیل یك آزمون محافظهكارانه را ترجیح داده باشم. اما اجازه نمیدهم مزاحم علاقه من برای مقایسههایی كه كاملاً به سطح معناداربودن نرسیدهاند بشود و آنها را در آزمایشهای بعدی بررسی میكنم.
دلیل من برای ارائه آزمونهای توكی و شفه آن است كه آزمون توكی برای مقایسههای دوتایی، مقایسه دو سطح در یك زمان حساستر از آزمون شفه است و احتمال بیشتری هست كه یك تفاوت را به عنوان معنادار بودن بپذیرد. اما آزمون شفه در مقایسههای پیچیده، تركیب سطوح و مقایسه سطوح تركیبی با سایرین، حساستر از آزمون توكی است همانند مقایسه 8 سالهها با تركیب 10 و 12 سالهها در آزمون رفتارهای اجتماعی.
آزمون توكی Tukey (برای همه مقایسههای دوگانه)
آزمون HSD توكی (تفاوت معنادار صادقانه) به ما اجازه می دهد هر جفت از سطوح را برای موجود بودن تفاوت معنادار بررسی كنیم. آنچه این آزمون انجام می دهد آن است كه به میزان تغییر تصادفی میان میانگین هر یك از این جفت ها نظر میكند، كه خطای استاندارد تفاوت میان میانگین جفتها باشد. اگر پس از آن ما تفاوت بین دو میانگین را با این خطای استاندارد مقایسه كنیم، یك آماره در دست داریم كه به ما میگوید كه تفاوت بین میانگینها در قیاس با تغییر تصادفی میان آنها چقدر بزرگ است. این آماره را q مینامیم.

اما در q ما از یك خطای استاندارد «همه منظوره» كه میتوان آن را برای هر جفتی به كاربرد استفاده میكنیم. مثل t میتوانیم توزیع q را تحت فرض صفر بیابیم. با استفاده از این توزیع میتوانیم تصمیم بگیریم كه یك تفاوت خاص در میانگینها با توجه به اینكه q محاسبه شده از مقدار q موجود در جدول برای سطح معنی داری انتخابشده تجاوز میكند، معنادار است یا خیر؟
آزمون توكی با قراردادن سطح معنی داری رویهم، که در آزمون های t چندگانه رخ می دهد، بر مشكل افزایش ریسك خطای نوع اول غلبه میكند. این بدان معناست كه ریسك خطای نوع اول در هنگام مقایسه هر جفت احتمالی مثلاً برابر 05/0 است. بنابراین آزمون توكی اجازه مقایسه هر جفت را به ما میدهد به شكلی كه میتوان q را برای هر جفت بدست آورد با علم به اینكه ریسك خطای نوع اول از 05/0 تجاوز نخواهد كرد.
در مثال آزمون رفتار اجتماعی چون چهار سطح داریم میتوانیم شش مقایسه انجام دهیم. اگر ما 4 گروه سنی داشتیم یعنی 6، 8، 10، 12 و 14 ساله همانگونه كه در یك F معنادار در آنالیز واریانس انجام دادیم، آزمون توكی به ما اجازه می داد كه 24 جفت مقایسه میان میانگینهای سطوح انجام دهیم.
فراتر از بدست آوردن مقدار q در هر موردی كه یك جفت از میانگینها را مقایسه میكنیم میتوان فرمول را به شكل زیر تغییرسازمان داد.

همه آنچه ما نیاز داریم نگاهكردن به q در سطح معنی داری انتخاب شده و بدست آوردن توكی HSD و به كار بردن آن برای هر کدام یا همه تفاوتها در میانگینهاست. اگر تفاوت در میانگینها بزرگتر از HSD باشد آنگاه تفاوت معنادار است (صادقانه!) .

یك مثال کاربردی
مثال كلمهسازی در فصل گذشته نمونه خوبی است زیرا ما در آن یك اثر معنادار از نوع راهنمایی در زمان حل معمای كلمهسازی یافتیم. مقدار F معنادار به ما اجازه انجام آزمونهای پُست هاک را می دهد تا ببینیم تفاوت میان کدام میانگین ها معنادار هستند. میانگینها در جدول زیر نمایش داده شدهاند.
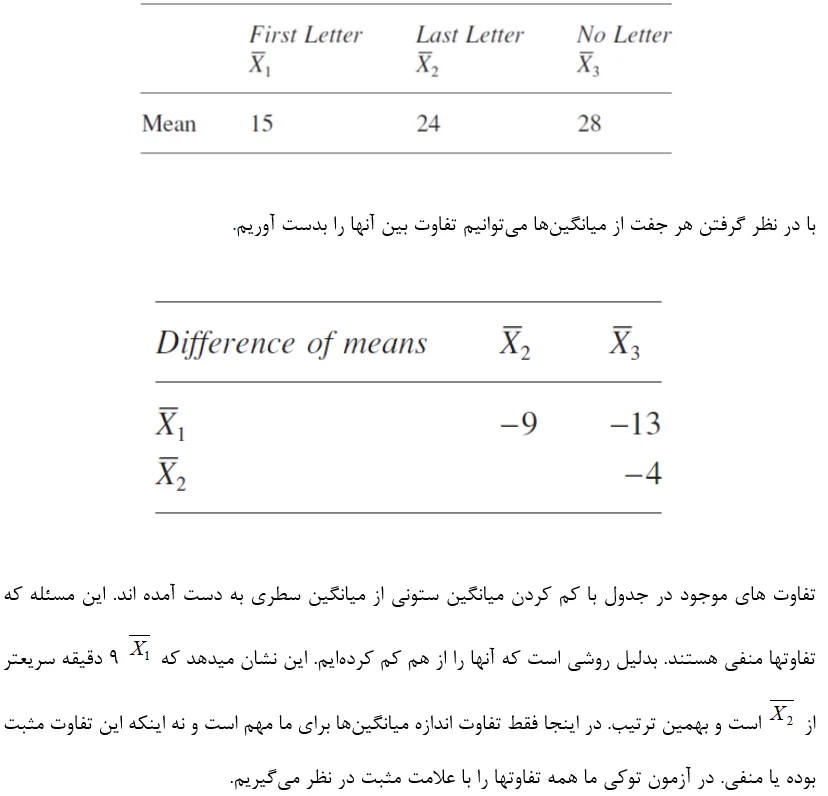

تفاوت بین سطوح راهنمایی با حرف اول و سطوح راهنمایی بدون حرف (13) و سطوح راهنمایی با حرف اول و راهنمایی با حرف دوم (9) در 05/0=P به شدت معنادار هستند زیرا هر دو از HSD بیشترند. تفاوت بین سطوح راهنمایی باحرف آخر و راهنمایی بدون حرف (4) در سطح 05/0=P معنادار نیست، اما تحقیقات بیشتر در این مورد ممكن است اثری را بیابد زیرا اختلاف در این مورد اگرچه به سطح معناداری نرسیده اما به آن نزدیك است. اكنون كه می دانیم كه تفاوت معنادار در كدام قسمت وجود دارد بررسی میكنیم كه به چه روشی تفاوت ایجاد میشود (كدام سطح زمان سریعتری تولید میكند) تا نتیجهگیری خود را كامل كنیم.
آنچه میتوان نتیجه گرفت آن است كه راهنمایی با حرف اول به صورت معناداری، زمان حل سریعتری از سطح حرف آخر و سطح بدون حرف دارد. زمان سطح راهنمایی با حرف آخر به صورت معناداری سریعتر از سطح بدون حرف نیست (اگرچه گرایش غیرمعناداری، برای اینكه سطح حالت حرف آخر میخواهد سریعتر باشد، نشان داده میشود)
خیلی آسان میتوانیم بازه اطمینان مقایسههایمان را بدست آوریم زیرا تفاوت میانگینها، مقدار بحرانی مناسب و همچنین خطای استاندارد را میدانیم (فصل 6 را برای معرفی بازه اطمینان ببینید). بنابراین میتوانیم بازه اطمینان را به صورت زیر بنویسیم.

جالب است كه توجه كنیم برای دو مقایسه اول، تفاوتها در طول بازه اطمینان سازگار بوده و حتی در بدترین حالت هم هنوز به اندازه كافی بزرگ است (96/4 و 96/8 ثانیه تفاوت). لیكن حالت سوم شامل صفر است بنابراین اگرچه در بهترین حالت اختلاف 04/8 ثانیهای به ما میدهد، اختلاف ممكن است همچنان صفر باشد.
اگرچه صفر به انتهای بازه نزدیك است ولی با اطمینان نمیتوانیم این احتمال را استثناء كنیم. بازه اطمینان یافتهها را به روش دیگری نسبت به آزمون معناداربودن توصیف میكند اما معنای یكسانی از هر دو برمیخیزد: یعنی ما میتوانیم مطمئن باشیم كه فقط دو تفاوت اولی، اختلافهای جمعیتی واقعی را اظهار میكنند.
آزمون شفه Scheffé (برای مقایسههای پیچیده)
بواسطه «مجموع مربعات بین گروهی » آزمون شفه، بخشی از آن را متناسب با مقایسه انجام شده محاسبه میكند. آنگاه از مجموع مربعات مقایسه میتوانیم به تولید میانگین مربعات و سپس مقدار F به طرف مقایسه برویم. این مقدار را میتوانیم با مقدار توزیع F مقایسه كرده تا ببینیم كه آیا مقایسه معنادار است یا خیر.
برای اصلاح افزایش ریسك خطای نوع اول كه میتواند از مقایسههای چندگانه ناشی شود، . مقدار F جدول را با توجه به اصلاح شفه تنظیم میكنیم. پیش از آنكه بتوانیم تفاوت معناداری بین حالات مقایسه شده را ادعا كنیم مقدار محاسبه شده F برای مقایسه میبایستی بزرگتر از مقدار اصلاح شده جدول باشد.
آزمون شفه سودمندترین آزمون برای مقایسههای پیچیده پست هاکی است. در مثال مهارتهای رفتاری اجتماعی كه در ابتدای این فصل آمد باید فرض كنیم كه محقق علاقمند بود كه تفاوتهای بین كودكان زیر 10 سال را با گروه كودكان 10 ساله بداند. در این صورت ما یك مقایسه مركب داریم زیرا دو گروه تركیب شدهاند (6 و 8 سالهها) تا با گروه 10 ساله مقایسه شوند، یك گروه هم (12 سالهها) از مقایسه كنار گذاشته شدهاند.

به دو طرف مقایسه وزن 1+ و 1- داده شده است (در واقع اعداد انتخاب شده برای ضرایب تا زمانیكه شرایط بالا در آنها صادق باشد میتوانند هر چیزی باشند مثلاً میتوانستیم 2+، 1- و 1- یا 10+، 5- و 5- را انتخاب كنیم. معمولاً عددهایی را انتخاب میكنیم كه محاسبهها را آسانتر كنند).
نتیجه انتخاب ضرایب تنها منجر به مجموع مربعات برای انجام یك مقایسه است. این مقایسه همیشه مابین دو سطح جدید بوده كه تركیبی از سطوح آزمایش شدهاند. در مثال بالا، دو سطح جدید عبارتند از: سطح اول اصلی آزمایش به عنوان سطح جدید اول و تركیبی از سطوح دوم و سوم كه دومین سطح جدید را تشكیل میدهند. از آنجائیكه همیشه دو طرف در مقایسه وجود دارد بنابراین درجه آزادی مقایسه همیشه برابر 1 است. در نتیجه میانگین مربعات مقایسه عبارت است از:



یك مثال کاربردی
در ابتدای این فصل بطور خلاصه درباره مطالعه مهارتهای اجتماعی كه بر روی چهار گروه مختلف سنی از كودكان انجام شده صحبت كردیم. در این آزمون محقق به دنبال تاثیر سن در مهارتهای اجتماعی است. تحلیل ما جدول خلاصه زیر را برای یك آنالیز واریانس با یک عامل اندازه گیری شده مستقل با مقدار F که در سطح بالایی معنی دار است تولید كرده است.
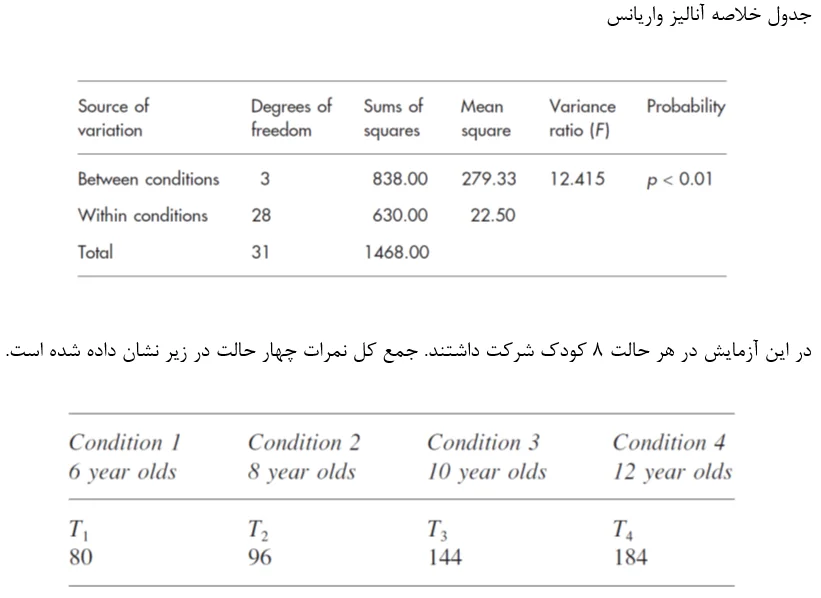
محقق تصمیم به انجام یك آزمون پست هاک گرفت تا بداند آیا تفاوت معناداری بین كودكان 10 ساله و كوچكترها یعنی تركیبی از 6 و 8 سالهها وجود دارد. برای تولید این مقایسه او ضرایب،، و را در نظر گرفت.
این ضرایب سطح چهارم را مستثنی كرده، سطح یك و دو را تركیب نموده كه در مقابل طرف دیگر مقایسه یعنی سطح سوم قرار میگیرند.
مجموع مربعات مقایسه از فرمول زیر محاسبه میشود.


مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




