آمار به زبان ساده – مقدمهای بر آنالیز واريانس
16 مهر 1400
دقیقه
پس از مطالعه فصل نهم آمار به زبان ساده – معنی داری، خطا و توان, در این فصل به آنالیز واریانس خواهیم پرداخت. فهرست محتوا پنهان عوامل و سطوح مشكل سطوح زياد و آزمونt چرا نمرات در يك آزمايش متفاوتند؟ تغییرات تصادفی در آزمایش تغییرات سيستماتيك در نمرات خطاهاي تصادفي و تفاوتهاي سيستماتيك محاسبه تغيير...

آخرین بهروزرسانی: 24 دی 1401
پس از مطالعه فصل نهم آمار به زبان ساده – معنی داری، خطا و توان, در این فصل به آنالیز واریانس خواهیم پرداخت.
آزمون t به دو دلیل محدود است. اول در يك زمان تنها اجازه مقايسه دو نمونه را ميدهد مثل مقايسه پيرمرد در برابر مرد جوان در يك كار خاص. در حالیکه در بسياري از حالات ما ميخواهيم كه تعدادي از نمونهها و نه فقط دو تا را با هم مقايسه كنيم مثل مرد جوان، مرد ميانسال و پيرمرد در يك كار خاص و آزمون t نميتواند اين كار را انجام دهد. دوم آنكه آزمون t تنها اثر يك متغير مستقل را در يك زمان مثل سن يا روش تدريس، بررسي ميكند در حاليكه ممكن است ما بخواهيم تركيب آنها را مقايسه كنيم. آنالیز واريانس شبيه آزمون t ولي بدون محدوديتهاي مذكور است. به اين دليل است كه آنالیز واريانس (يا آنوا) يك تكنيك آماري مشهور درمحدودهاي از زمينههاي تحقيقاتي است.
عوامل و سطوح
در فصلهايي كه پس از اين خواهد آمد من به متغيرهاي مستقل عامل اطلاق خواهم كرد زيرا اين اصطلاحیست كه در آنالیز واريانس به كار ميرود بنابراين سن، رنگ مو و نوع مدرسهاي كه در آن درس خوانده ميشود همه مثالهايي از عوامل هستند. سطوح دستهاي متغيرهاي مستقل هستند كه ما براي مطالعه برگزيدهايم. همچنين به اينها عناوين ديگر مثل گروهها، دسته ها يا تیمارها نيز گفته ميشود. اما من عبارت سطوح را به كار ميبرم. اگر ما تأثير متغير مستقل را بررسي ميكنيم بايد سطوح را انتخاب نمائيم: 20 سالهها، 40 سالهها و 60 سالهها. اين گروههاي سني شرايط سه گانه عاملی هستند كه بررسي ميكنيم. البته ما اگر بخواهيم ميتوانيم سطوح ديگري براي متغير سن كه آن را بررسي ميكنيم برگزينيم.
مشكل سطوح زياد و آزمونt
به موقعيتي كه در آن شما ميخواهيد بيش از دو سطح را بررسي كرده توجه نمائيد علاوه بر مقايسه كودك يك مدرسه بزرگ، ممكن است بخواهيد تعدادي از مدارس مختلف را با هم مقايسه كنيد (كه ميتوانيم آنها را با برچسبهاي A، B، C، … مشخص كنيم). بطور مشابه ممكن است بخواهيد سه روش تدريس (A، B، C) را روي يك گروه از كودكان مقايسه كنيد. مسئله آن است كه راهی بيابيم تا بتوانيم يافتههايمان را به صورت آماري تحليل كنيم يك راه حل آن است كه تعدادي آزمون T انجام دهيم. يعني هر جفت از سطوح را با هم مقايسه كنيم A،B، B و C وA وC البته وقتيكه سه شرط داشته باشيم. اما به دلايل زير اينكار را نخواهيم كرد.
ما بايد به جاي يك آزمون، سه آزمون انجام دهيم اگر چهار شرط داشته باشيم ميبايستي شش آزمون مختلف و اگر ده سطح موجود باشد ميبايست 45 آزمون مختلف انجام پذيرد ما واقعاً به يك آزمون نيازمنديم كه اجازه دهد بيشتر از دو سطح را به صورت همزمان مورد بررسي قرار دهيم. در حقيقت يك آزمون كه يكبار آنرا انجام دهيم و نه چهل و پنج بار.

چرا نمرات در يك آزمايش متفاوتند؟
اگر به مجموعهاي از دادهها نظر بيفكنيم در مييابيم كه همه دادهها يكسان نيستند. چرا اين تغييرپذيري در دادهها وجود دارد؟ پاسخ به اين سوال كليد علت به كار بردن آنالیز واريانس به عنوان ابزاري براي آزمون فرض را در خود دارد. اجازه دهيد براي روشن شدن موضوع مثالي بزنيم. ميخواهيم تا اثر تكرار يك لغت در يك زبان را در زمان بازي جملهسازي بدانيم. سطوح مختلفي چون، لغت شايع، لغت كمتر رايج و لغت نادر را انتخاب ميكنيم. ميتوانيم از يك برنامه بانك لغات كامپيوتري آن زبان (كه از طريق اينترنت در دسترس است و ميزان تكرار يك لغت را در محدوده وسيعي از متون آن زبان نشان ميدهد) استفاده ميكنيم تا لغات متناسب با سطوح خود را انتخاب كنيم. در انتخاب لغات بايد مطمئن شويد كه فقط از لحاظ تعداد تكرار متفاوت هستند ولي از نظر طول كلمه يا ديگر عوامل اختلاط گر تفاوتي با هم ندارند. پس از آن زماني را كه شركتكنندگان در هر کدام از سطوح سه گانه بتوانند جملهاي را بسازند مي گيريم. فرض صفر پيشبيني ميكند كه همه نمرات در سطوح سه گانه از يك توزيع ميآيند. اگر تفاوتهاي ميان ميانگينهاي سطوح سه گانه باشد آيا ميتوان فرض صفر را رد كرد و ادعاي يك تفاوت واقعی بين توزيعهاي زمان جمله سازي را با توجه به تعداد تكرار لغات در زنان مطرح نمود. متأسفانه خير، زيرا حتي وقتيكه فرض صفر صحيح باشد نيز در مييابيم كه نميتوانيم در سطوح گوناگون ميانگينهاي مساوي داشته باشيم. آنچه نیاز است بدانیم، دلیل ایجاد تفاوت در نمرات و اینکه زمانیکه دلایل زیادی مانند دستکاری عامل ها، فراوانی لغات وجود دارد، چگونه می توان چنین تغییری را یافت، با فرض اینکه دلایلی دیگر، حتی زمانیکه فرض صفر صحیح باشد، مانند تغییرات تصادفی که انتظار داریم وجود نداشته باشند.
تغییرات تصادفی در آزمایش
احتمال کمی وجود دارد که زمان ثبت شده توسط شرکت کنندگان در سطحی مشابه برای ساختن جمله دقیقا یکسان باشد. نمرات از یک توزیع می آیند و بعضی از شرکت کنندگان سریع هستند و برخی دیگر آهسته و هر کدام از این افراد بدون در نظر گرفتن سایرین در ساختن میانگین جمعیت نقش دارند. نتیجه ای که به دست می آوریم بر اساس یک نمونه از نمرات جمعیت به دست می آید و حتی اگر نمونه ی انتخابی ما به صورت تصادفی از جمعیت انتخاب شود باز هم احتمال ایجاد خطاهای تصادفی و غیرسیتماتیک وجود دارد که می تواند منجر به تفاوت هایی در نمرات و تفاوت هایی بین میانگین نمونه و جمعیت شود. حتی زمانیکه فرض صفر صحیح است انتظار داریم نمرات در سطوح متفاوت به دلیل خطای تصادفی اختلاف داشته باشند و میانگین این سطوح به همین دلیل ذکر شده متفاوت باشد.
وقتيكه نمرات از عنوان های موضوعی مختلفي ميآيند يك دسته عمده از خطاهاي تصادفي ناشي از تفاوتهاي فردي است يعني شركتكنندگان در قابليت جملهسازي، تجربه حل جدول و مثل آن با هم متفاوت هستند. از اين مسئله متوجه ميشويم كه چرا بايد به صورت تصادفي افراد را از اين جمعيت انتخاب كنيم. اگر انتخاب ما از راه نادرستي باشد مثلاً فقط افراد خبره در حل جدول را برگزينيم آنگاه زمان آنها به صورت سيستماتيك از ميانگين جمعيت منحرف شده و باعث ميگردد كه برآورد ضعيفي از آن باشد و ما قادر نخواهيم بود كه اين نتايج را عمومي كرده و به جمعيت وسيعتري تعميم دهيم.
به همان اندازه تفاوتهاي فردي مجموعهاي از خطاهاي تصادفي ديگر وجود دارد كه علت آن دشوار بودن تنظيم شرايط مساوي براي شركتكنندگان است. مداد يك نفر ممكن است بروي زمين بيفتد، ديگري ممكن است واژهاي از جدول روزانه صبح را به ياد آورد و حواس نفر سوم ممكن است با صدايي پرت شود. اينها ميتوانند بر روي زمان جملهسازي تأثير بگذارند. بنابراين ما بايد انتظار داشتهباشيم نمرات در يك آزمايش بدليل خطاهاي تصادفي صرفنظر از اينكه فرض صفر صحيح باشد يا نه، متفاوت باشند.
تغییرات سيستماتيك در نمرات
اگر فرض صفر صحيح باشد و هيچ تفاوتي در جمعيت مثال جملهسازي در سطوح مختلف تكرار لغت در زبان وجود نداشته باشد آنگاه هر تفاوتي كه ميان ميانگينهاي سطوح مختلف بيابيم بايد تنها به دليل خطاهاي تصادفي باشد. ليكن وقتيكه فرض صفر نادرست باشد نمرات سطوح مختلف ممكن است از جمعيتهاي متفاوتي آمده باشند (بر خلاف نمرات يك سطح)، در چنين حالتي ما بايدتفاوت سيستماتيك بين سطوح را پيدا كنيم. در این حالت ما با تعمق بیشتری نمرات را در زمینه جمله سازی انتخاب کرده ایم و آنها در رابطه با فراوانی لغات میان سطوح مختلف متفاوت هستند. اگر جملهسازي با يك لغت رايج و شايع سادهتر از جملهسازي با کلماتی غیر رایج تر است آنگاه باید انتظار داشته باشیم که این تفاوت در میانگین جمعیت در نمرات ما منعکس شود. اگر فراوانی لغت روی زمان اثر بگذارد انتظار می رود که تفاوت های سیستماتیکی در نمرات بین سطوح مختلف وجود داشته باشد. (كه به عنوان يك اثر تیماری شناخته ميشود) اين همان چيزيست كه ما به دنبال آن ميگشتيم، شواهدي كه دلالت بر وجود تفاوت در ميانگينهاي جمعيتها در جملهسازي با سطوح مختلف دارد.
خطاهاي تصادفي و تفاوتهاي سيستماتيك
نمرات يك آزمون به خاطر خطاهاي تصادفي و سيستماتيك متفاوت خواهند بود. اگر ما عنوان های موضوعی خود را به صورت مناسب برگزيده باشيم بايستي انتظار داشته باشيم كه خطاهاي تصادفي در هر جايي از دادهها و نه فقط متمركز در يك شرايط خاص، اتفاق بيفتند. به هر حال اگر اثر واقعی از متغيرهاي مستقل وجود داشته باشد كه بر نمرهها تأثير بگذارد آنگاه ميبايستي انتظار تفاوت سيستماتيك بين نمرات در سطوح مختلف را داشته باشيم. خطاهای تصادفی سطح معینی از تغییرپذیری را در نتایج در هر دو بخش درون گروهی و بین گروهی که به نوعی یک خطای زمینه ای است، ایجاد می کنند. چنانچه فرض صفر نادرست بوده و تفاوت هایی میان سطوح وجود داشته باشد انتظار می رود که این مسئله تفاوت های سیستماتیکی در نمرات به دست آمده از سطوح مختلف حتی بیش از خطای زمینه ای ایجاد کند.
به نتایج به دست آمده از سه مثال که در جدول زیر آمده است توجه کنید.
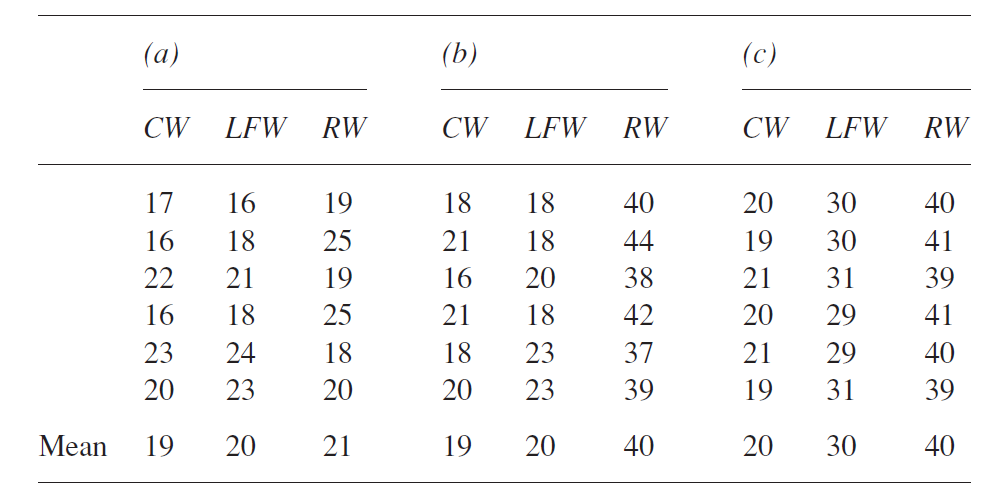
(حروف کوتاه CF، LFW و RW در جدول به ترتیب بیان کننده ی لغات اغلب استفاده شده، لغات با فراوانی کمتر و لغات به ندرت استفاده شده هستند. نمرات بر حسب دقیقه اندازه گیری شده اند.)
چه چیزی را می توان به عنوان دلیل تغییر پذیری نمرات در میان سه مثال a، b و c بیان کرد؟ نکته کلیدی تصمیم در مورد وجود تغییر پذیری میان نمرات در سطوح است. در مثال a تغییراتی فقط به اندازه یک واحد میان میانگین سطوح وجود دارد. در این مثال با اینکه هم نمرات کوچک و هم نمرات بزرگ در هر سه سطح داریم خطای زمینه ای بسیار کوچکی در تغییر پذیری تصادفی وجود دارد. چنین نتایجی زمانی رخ می دهند که فرض صفر صحیح بوده و تفاوتی واقعی بین جمعیت هایی که نمونه ها از آن استخراج شده اند وجود ندارد. مثال b دلالت بر تغییری ضمنی دارد، یعنی فقط بین لغات با کاربرد به ندرت با سایر سطوح تفاوت وجود دارد. همه ی نمرات در سطح کلمات با کاربرد به ندرت بالا هستند و میانگین آنها 40 بوده که حداقل 10 واحد از میانگین سطوح دیگر تفاوت دارد و نشان از تغییر پذیری بیشتر در این داده ها است که می تواند به تنهایی از تغییر پذیری تصادفی ناشی شده باشد. این مثال تفاوت ضمنی میان توزیع جمعیت ها کلمات با کاربرد به ندرت با دو سطح دیگر را نشان می دهد در حالیکه که تفاوت چندانی میان کلمات رایج با کلمات با کاربرد کم وجود ندارد.
در نهايت در مثال (C) ما تفاوت بزرگي بين ميانگين هر سه گروه داريم كه بنظر ميرسد بر هر تغيير پذيري تصادفي غلبه داشته باشد و دلالت بر آن درد كه هر سه نمونه از توزيعهاي متفاوتي آمدهاند. آنچه اكنون نياز انجام دهيم ايجاد يك آماره است كه تحلیل رسمی و قراردادی از تغییر پذیری نمرات در یک آزمایش ارائه دهد، که در واقع یک روش معادل آن همان روش بررسی غیر رسمی چشمی است که در مثال بالا مشاهده کردیم و این روش جدید به ما اجازه می دهد تصمیم بگیریم چه زمانی تغییر پذیری نمرات در سطوح نشاندهنده ی تفاوت واقعی میان جمعیت هاست (همانند آنچه درمثال b وc آمده)و چه زماني بر تغييرات تصادفي مورد انتظار بوسيله شانس، وقتيكه فرض صفر صحيح است (مثال a) دلالت ميكند.
محاسبه تغيير پذيري نمرات
لازم است كه تغييرپذيري نمرهها را به صورت آماري بيان كنيم. تاكنون ما از انحراف استاندارد براي انجام اين کار از انحراف استاندارد برای یک نمونه از نمرات استفاده کرده ایم.
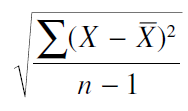
اكنون مايليم كه منابع متفاوت تغييرپذيري را مقايسه كنيم تا دريابيم كه آيا تفاوتهاي سيستماتيك علاوه بر تغييرپذيري تصادفي در داده وجود دارد يا خير نه اينكه فقط بدنبال جستجوي يك انحراف استاندارد از ميانگين باشيم. به همين خاطر و بخاطر آنكه ما نمی خواهیم با ریشه ی دوم سر و کار داشته باشیم، ساده تر است که که از واریانس که در واقع همان مربع انحراف استاندارد است استفاده کنیم:
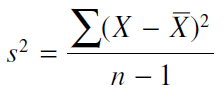
واریانس نمونه در دل محاسبه واریانس مجموع مربعات وجود دارد:
![]()
که معیار تغییر پذیری نمرات از میانگین نمونه است. زمانیکه نمرات تغییرات زیادی از میانگین نمرات داشته باشند مجموع مربعات بزرگ و هنگامی که نمرات به صورت خوشه ای اطراف میانگین توزیع شده باشند مجموع مربعات مقداری کوچک خواهد بود.اين آن چيزي است كه ما براي تحليل تغييرپذيري خود نياز داريم.
مجموع مربعات از تعداد نمرات نمونه نيز تأثير ميپذيرد. هر چه تعداد نمرات بيشتر باشد، مجموع مربعات نيز بزرگتر خواهد بود حتي اگر تغييرپذيري نمرات بزرگتر نشود چون هر نمره اضافي (مگر اينكه دقيقاً مساوي ميانگين باشد) به آن افزوده خواهد شد. به دو نمونه با عناوين نمونه 1 با نمرات 1، 1، 2، 3، 3 و نمونه 2 با نمرات 1، 2، 3 توجه كنيد. تغيير پذيری دو نمونه با نمراتي كه از ميانگين بيشتر از يك واحد انحراف ندارند بنظر يكسان ميآيد. از جدول زير ميتوانيم ببينيم كه چون تعداد نمرات نمونه 1 بيشتر بوده، جمع مربعات آن نيز بزرگتر خواهد بود.

براي در نظر گرفتن اين مسئله است كه لازم است مجموع مربعات را بر درجه آزادي df=n-1 تقسيم كنيم تا يك متوسط از تغييرپذيري يك نمره در نمونه بدست آوريم. (از فصل 5 بياد بياوريدكه ما درجه آزادي را به آن دليل به كار ميبرديم چون برآورد بهتري از پارامترهاي جمعيتي كه به آن علاقمنديم به ما مي دهد). در نمونه1، پنج نمره وجود دارد بنابراين n=5 و df=n-1 ميشود كه حاصل آن واريانسي معادل 1 است. در نمونه 2، n=3 و df=2 بوده آن هم واريانسي معادل 1 به ما ميدهد. اين با نظر ابتدايي ما كه گفتيم تغييرپذيري اين دو نمونه يكسان به نظر ميرسند مطابقت ميكند.
ما علاقمند به يك تغييرپذيري هستيم كه بوسيله فاكتورهاي مختلفي از داده ها توليد شود: مانند خطاي تصادفي و تفاوتهاي سيستماتيك، و ما ميتوانيم فرمول واريانس را براي يافتن آن به كار ببريم.
فرآیند تحليل تغييرپذيري
نكته مفيد درباره مجموع مربعات آن است كه ميتوانيم براي بخشهاي مختلف دادهها محاسبه كنيم. ميتوانيم مجموع كل مربعات را با در نظر گرفتن تك تك نمرات صرف نظر از سطح بدست آوريم. با استفاده از دادههاي زير، ميانگين كلي برابر 10 بوده و با در نظر گرفتن همه 18 نمره مجموع مربعات ما برابر 328 خواهد شد.
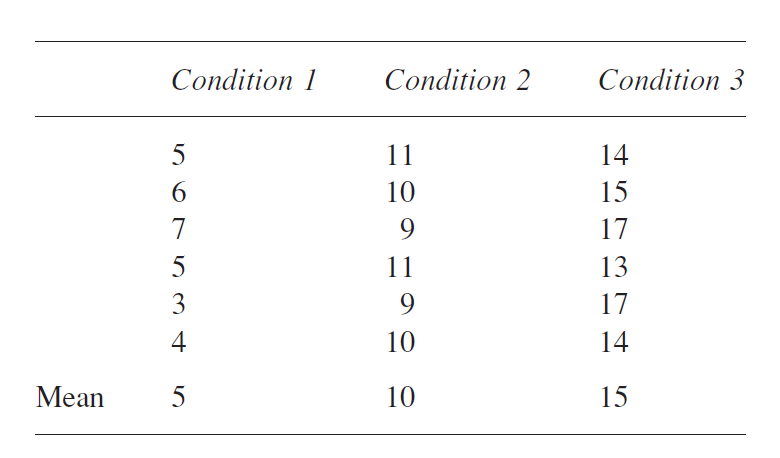
همچنين ميتوان مجموع مربعات را براي نمرات در يك سطح خاص محاسبه كرد. نمرات سطح
1 ميانگيني برابر 5 داشته و مجموع مربعات 6 نمره آن برابر 10 است، براي سطح ميانگين 2 و مجموع
مربعات 4 و براي شرايط 3 مجموع مربعات 14را داريم
اگر اينها را با هم جمع كنيم به ما معیاری از تغییر پذیری نمرات درون سطوح را خواهد داد. مجموع مربعات «درون گروهی» بنابراين مساوي 28 خواهد بود (14+4+10).

از آنجايیكه ميتوانيم هر دوي مجموع مربعات و درجه آزادی به اجزایی جدا كنيم بنابراين ميتوانيم واريانس درون و بین گروهی را نيز محاسبه كنيم.
نسبت واريانس
آنچه ما ميخواهيم بدست آوريم آن است كه چه مقدار تغييرپذيري در آزمايش ما ناشی از دستکاری است، يعني تفاوتهاي سيستماتيك بین گروهی. واريانس بین گروهی به ما ميگويد كه متوسط تغييرپذيري ميان سطوح چقدر است. اين مقدار از تفاوت سيستماتيك ميان وجود باشد) بعلاوه خطاهاي تصادفي (كه در هر حالت پيش ميآيد) ناشي ميشود. اين مقدار به تنهايي براي شناسایی تفاوت در جمعيتها كافي نيست زيرا اين واريانس ممكن است به بيش از يك دليل بزرگ باشد. تفاوتهاي سيستماتيك ممكن است بزرگ باشند يا خطاهاي تصادفي ويا هر دو. آنچه اكنون لازم است انجام دهيم برآورد اندازه تغييرپذيري ناشی از خطاهاي تصادفي است.
درون یک سطح نمرات فقط به دليل خطاهاي تصادفي و نه تفاوتهاي سيستماتيك متغيرند (از آنجائيكه عناوین موضوعی درون یک سطح در شرايط يكساني عمل ميكنند ما متغير مستقل را درون یک سطح دستكاري نميكنيم ) فرض كنيد خطاهاي تصادفي بر همه نمرات به صورت مساوي اثر ميگذارند (در غير اينصورت تصادفي نخواهند بود) ميتوانيم واريانس درون سطوح را به عنوان برآوردی از واریانس ناشی از خطای تصادفی یا همان واریانس خطا در نظر بگیریم.
چنانچه واریانس بین گروهی را با واریانس درون گروهی مقایسه کنیم، آماره ای برای شناسایی تغییرات سیستماتیک میان سطوح در صورتیکه وجود داشته باشند خواهیم داشت . این آماره را F نامیده که در واقع همان نسبت واریانس است:
این آماره همچنین به صورت زیر می تواند بیان شود:
توجه كنيد كه تنها تفاوت بين معادله بالا و پائين تفاوتهاي سيستماتيك بین سطوح است که واریانس خطای موثر بوده و هر دو معادله را به صورت يكسان تحت تأثير قرار ميدهد. اگر تفاوت سيستماتيكي بين سطوح وجود داشته باشد بوسيله يك مقدار بزرگ از F نشان داده خواهد شد. به همين ترتيب اگر فرض صفر صحيح بوده و تفاوتي ميان توزيعهايي كه نمونهها از آنها ميآيند وجود نداشته باشد آنگاه ما بايد انتظار داشته باشيم كه نتوان تفاوت سيستماتيكي بين سطوح يافت، بنابراين وقتيكه فرض صفر صحيح است انتظار داريم كه:
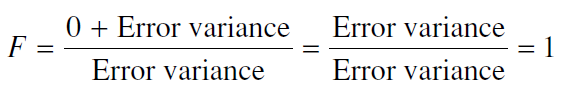
هنگاميكه فرض صفر صحيح باشد انتظار داريم F برابر يك شود زيرا بالا و پائين معادله يكسان هستند. اما در هنگام خطابودن فرض صفر انتظار داريم كه تفاوت سيستماتيكي بين سطوح بيابيم و F بزرگتر از يك باشد، هر چه تفاوت سيستماتيك بزرگتر باشد مقدار F بزرگتري توليد خواهد كرد.
توزيع F
به صورت واضح براي سطح معنی داری ای كه برگزيدهايم لازم است بدانيم كه مقدار محاسبه شده براي F چقدر بايد بزرگ باشد تا بتواند معنا دار باشد. آنچه لازم است بدانيم توزيع نمونهگيري F وقتي كه فرض صفر صحيح باشد است. اگر نمونههايي از همان توزيع شرايط آزمايشي خود برگزينيم و F را محاسبه نمائيم چه مقداري از F بدست خواهيم آورد. ؟
اول مقدار F در اطراف 1 خواهد بود زيرا خطاي سيستماتيكي بين سطوح وجود ندارد و دو واريانسي كه معادله را ميسازند بنظر ميآيد كه به احتمال زياد مساوي باشند. دوم F هرگز كمتر از صفر نخواهد بود زيرا نسبتي از عددهايي است كه مربع شدهاند و مربعها هرگز منفي نيستند. اين همچنين به آن معناست كه ما به یک توزیع F فقط با یک دنباله علاقمنديم يعني هر قدر كه F بزرگتر از يك بوده بايد مقداري باشد كه فرض صفر را رد كند.
همانند توزيع t، F نيز يك برآورد است. ما واريانس نمونه را براي برآورد مقدار موجود در جمعيت به كار ميبريم. مجدداً همانند t، دقت اين برآورد بستگي به درجه آزادي برآورد دارد.
برخلاف t، آماره ی F وابسته به دو واریانس است، واریانس بین گروهی و واریانس خطا، بنابراین تحت تأثیر هر دو درجه آزادی قرار خواهد گرفت. خوشبختانه توزیع F توزیعی شناخته شده است و مقادیر بحرانی برای سطوح معنی داری در هر ترکیبی محاسبه شده اند (جدول A.3 از پیوست).
در نتيجه ميتوانيم مقدار محاسبه شده F خود را با مقدار متناسب در جدول مقايسه كنيم تا تصميم بگيريم كه تفاوتهاي معنادار بين سطوح وجود دارد يا خير؟
تصوير 1-10 مثالي از توزيع F (درجه آزادي = 4,8)
براي استفاده از توزيع F براي مقايسه باید مفروضاتي را بپذيريم: نمونههاي سطوح از جمعيتهايي با توزيع نرمال ميآيند، نمونهها از توزيعهايي با واريانسهاي مساوي ميآيند و نمونه به صورت تصادفي برگزيده شدهاند. اينها خيلي شبيه همان مفروضاتي هستند كه در آزمون t داشتيم. وقتيكه تحليل واريانس را انجام ميدهيم اين سه فرض را نيز بايد بپذيريم در غيراينصورت ممكن است مقايسه مقدار محاسبه شده F با مقادير موجود در جداول مناسب نباشد.
عجيب نيست كه در طول اين بخش گفتهام مثل t، زيرا رابطهاي سادهاي در اين حالت رابطه ای ساده بين توزیع F و t وجود دارد که می توان به مقایسه آن ها پرداخت. (با دو سطح) توضيحي در اين زمينه در فصل آينده ميآيد. تصوير 1.10 مثالي از يك توزيع F را نشان ميدهد. اين ممكن است عجيب به نظر بيايد اما تصور كنيد همه نمرات در يك توزيع (همانند آنچه در تصوير 6.2 است) به توان 2 رسيدهاند. همه مقادير منفي مثبت خواهند شد و مانند شكل 10.1 تبديل به يك توزيع F خواهد شد. نكته ديگر براي توجه به آن كه F از مربع نمرات ساخته شده اين است كه ما ديگر تفاوتي بين آزمون يك دمي و آزمون دو دمي نداريم. مقادير مربع به اين معناست كه هر تفاوتي ميان میانگین سطوح به مقدار F افزوده خواهد شد. پيشبيني ما براي F به سادگي آن است كه در جايي تفاوتهاي سيستماتيك معناداري بين سطوح وجود دارد. يك مقدار بزرگ براي F ميتواند به آن معنا باشد كه همه سطوح به صورت معناداري از يكديگر متفاوتند يا اينكه يكي از آنها با سایرین متفاوت است. اغلب تحقيقات بيشتري براي الصاق معناي «يك مقدار معنادار F» نياز است.
نتيجهگيري
با مطالعه در تغييرپذيري دادهها ما يك آماره توليد كرديم يعني نسبت واريانس F كه واريانس را از جهت فاكتورهاي مختلف در دادهها تحليل ميكند. واريانس بین گروهی شامل تفاوتهاي سيستماتيك بين سطوحی است كه ما به دنبال آنها ميگرديم. این شاخص همچنين شامل خطاهايي تصادفي ست كه ما انتظار داريم همراه هر دادهاي كه جمع ميكنيم باشد. خوشبختانه ميتوانيم اين واريانس خطا را با دنباله روی در دادههايي كه توسط تفاوتهاي سيستماتيك بین گروهی تحت تأثير واقع نشدهاند يعني واريانس درون گروهی ، برآورد کنیم. وقتيكه نسبت اين دو واريانس را ميآزمائيم يك آماره داريم كه برآوردی از تفاوت سيستماتيك بین گروهی به ما مي دهد. اگر مقدار محاسبه شده F از مقدار بحراني توزيع F در سطحي كه ما برگزيدهايم (مثلاً 05/0 يا 01/0=P) آنگاه ميتوانيم فرض صفر را رد كرده و نتيجه بگيريم كه حداقل میان بعضی سطوح تفاوت معنی داری وجود دارد.
با انجام آنالیز واريانس ديگر نگران مشكل افزايش ريسك خطاي نوع اول نخواهيم بود زيرا همه سطوح در يك آزمون در يك سطح معنی داری انتخاب شده، مقايسه ميشوند. در فصل بعدي خواهيم ديد كه چگونه آنالیز واريانس ميتواند براي تحليل دادههایی با انواع طرح های آزمایشی به كار برده شود.
مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




