مقدمه ای بر تحليل ناپارامتری
01 آذر 1400
دقیقه
در فصل سیزدهم مقاله آموزشی آمار به زبان ساده به محاسبه آنالیز واریانس دو عاملی پرداختیم. در این فصل به آموزش تحليل ناپارامتری در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم. فهرست محتوا پنهان چرا نمی توان فرض کرد که مقیاسی که معلم جهت امتیاز دهی استفاده کرده است یک مقیاس فاصله ای...

آخرین بهروزرسانی: 24 دی 1401
در فصل سیزدهم مقاله آموزشی آمار به زبان ساده به محاسبه آنالیز واریانس دو عاملی پرداختیم. در این فصل به آموزش تحليل ناپارامتری در ادامه سری مقالات آموزشی آمار به زبان ساده می پردازیم.
موقعیت زیر را در نظر بگیرید. محققی علاقه مند به بررسی چگونگی تغییرات احتمالی میان دختران و پسران در یک کلاس است. یکی از فرضیه های مورد آزمون محقق با دقت تر بودن دختران نسبت به پسران است. مسئله ای که در این راه وجود دارد عدم داشتن تصویری تلویزیونی از کلاس و ثبت یافته ها برای کلاسی از کودکان است که از طرفی مناسب جهت این آزمون بوده و از طرف دیگر در دسترس محقق می باشد. با اطلاع از همه این مسائل محقق تصمیم دارد که به نظر معلم به عنوان راه حل اعتماد کند. از معلم خواسته شده است که به هر کدام از کودکان بر حسب میزان توجهی که دارند نمره ای بین 0 تا 100 بدهد. به دلایلی موجه تا انتهای کار معلم از فرضیه آزمون اطلاعی ندارد. در یک کلاس ده نفره از کودکان نتایج زیر به دست آمد:
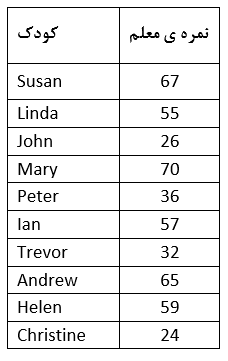
در بخش بعد نتایج با مقیاسی بین 0 تا 100 نمایش داده شده اند و بیانگر امتیاز اولیه ای است که معلم به هر کدام از کودکان نسبت داده است. هر چند که اگر به صورت بصری نگاهی به نتایج داشته باشیم به نظر می رسد که دختران از دقت بالاتری برخوردارند، اما در انتهای امر متوجه می شویم که نتیجه برعکس است. چنانچه نوعی ترتیب در این داده ها وجود داشت، می توانستیم نتایج بدست آمده را با آزمون t مقایسه کنیم.

مشکلی که وجود دارد این است که فرضیه ای مورد استفاده قرار گرفته است که ممکن است معتبر نباشد. مشکل در ارتباط با چگونگی استفاده از سیستم و مقیاس امتیاز دهی است. بر اساس داده ها به نظر می رسد که تفاوت ناچیزی میان کریستین و جان ولی تفاوت قابل توجهی بین مری و لیندا وجود دارد. همچنین تفاوت بین کریستین و جان برابر با 2 بدست آمده است که مشابه با تفاوت میان اندرو و سوزان است. فرض این است که معلم جهت امتیاز دهی از مقیاسی فاصله ای استفاده کرده است که در آن داده ها در طول مقیاس در فواصل مساوی افزایش می یابند و همیشه تفاوت بین اعداد متوالی یکسان است. (مراجعه شود به فصل 2 در ارتباط با انواع متفاوت داده ها)
چرا نمی توان فرض کرد که مقیاسی که معلم جهت امتیاز دهی استفاده کرده است یک مقیاس فاصله ای است؟
دو دلیل وجود دارد. اول اینکه معلم نه ساعت است نه یک دماسنج و نه یک نوار اندازه گیری. اینها همه دستگاه هایی هستند که با نیروی فکر جهت اندازه گیری هایی در فواصل مساوی طرح ریزی شده اند. انسان ممکن است قادر به قضاوت میان تفاوت ها به صورت رسمی را مانند سایر دستگاهها نداشته باشد. دوم اینکه نمی توان همانگونه که ساعتی را جهت بررسی کارکردن صحیح مورد بررسی و اندازه گیری قرارمی دهیم، معلم را نیز بررسی کرد.
در حقیقت ممکن است معلم گمان کند که کریستین و جان در مقایسه با اندرو و سوزان بیشتر به یکدیگر شباهت دارند. همچنین اگرچه اختلاف میان پیتر و لیندا از نظر عددی بزرگتر است، از نظر معلم ممکن است تفاوت میان پیتر و لیندا به اندازه ی تفاوت جان و تریور باشد. بنابراین به نظر می رسد که مقیاس فاصله ای مورد استفاده قرار نگرفته است. مشابه با یک نوار اندازه گیری که از مواد سخت ساخته شده است، در مقیاس فاصله ای نیز به نوعی همان سخت گیری وجود دارد و فواصل همیشه مشابه هستند. اکنون یک نوار اندازه گیری ساخته شده از مواد ارتجاعی را در نظر گیرید. “نوار اندازه گیری” معلم (مقیاس امتیاز دهی) ممکن است به بعضی افراد بها خاصی داده در حالیکه توانایی های سایرین را نادیده بگیرد و سبب ایجاد مقیاسی متفاوت شود. در حقیقت مقیاس امتیاز دهی معلم ممکن است مشابه با مقیاس زیر باشد.
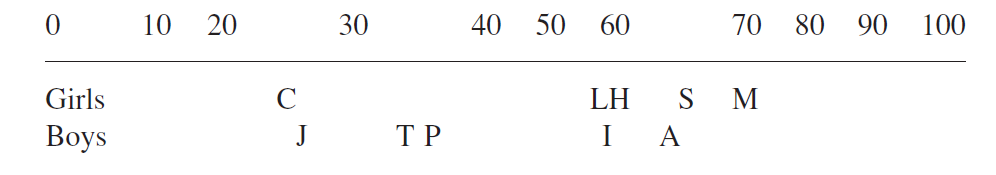
زمانی که فاصله ای بودن یا نبودن یک مقیاس مورد تردید باشد، باید فرض را بر این بگذاریم که فاصله ای نیست، زیرا در غیر این صورت ممکن است تجزیه و تحلیل داده ها در معرض خطای نتیجه گیری قرار گیرند. متأسفانه این امر مشکل دیگری را ایجاد می کند. همه ی آزمون فرضیاتی که تاکنون در این کتاب مورد بررسی قرار گرفته اند (آزمون نرمال استاندارد، آزمون تی و آنالیز واریانس)، فرض می کنند که متغیر وابسته با مقیاس فاصله ای اندازه گیری شده است. در حقیقت به این فرض به دلیل صحت در محاسبه ی صحیح آماره هایی مانند میانگین، انحراف استاندارد و سایر آماره ها نیاز است. بدون مقیاس فاصله ای همچنین محاسباتی بی معنی است.
در این قسمت می توان به دو نوع داده اشاره کرد: یکی که بر اساس مقیاسی فاصله ای بوده و می توان به محاسبه آماره ها پرداخت، دیگری یک مقیاس ترتیبی است. داده های فاصله ای معمولا از آزمایشاتی که در آنها متغیر وابسته با استفاده از دستگاه های اندازه گیری رسمی اندازه گیری می شوند به دست می آیند مانند زمان واکنش، کاهش وزن، نمرات یک آزمون خاص و غیره. در مورد این داده ها می توان آزمون های پارامتری مانند آزمون تی و یا آنالیز واریانس استفاده کرد. دیگر ویژگی برجسته ی آزمون های پارامتری این است که فرضیاتی پارامتری را می سازند که در ارتباط با جمعیتی که نمونه از آن بدست آمده است می باشد؛ که شامل مفروضاتی مانند توزیع نرمال جمعیت و اینکه نمونه ها از توزیع هایی با واریانس مساوی استخراج شده اند. کلیه ی آزمون ها در تلاش برای برآورد کردن پارامترهای نامعلوم جامعه با استفاده از آماره های نمونه هستند و این پارامترها توسط مفروضاتی محدود می شوند. چنانچه باور داشته باشیم که فرضیات آزمون پارامتری مناسب و کافی نیستند بکارگیری آنها صحیح نیستند و ممکن است آزمون فرض به درستی صورت نگیرد. زمانی که این نگرانی وجود دارد که داده ها فاصله ای نباشند یا فرضیات پارامتری معتبر نباشند آزمون های ناپارامتری به عنوان جایگزینی به کار می روند که نیاز به هیچکدام از فرض فاصله ای بودن در مورد مقیاس اندازه گیری و یا مفروضاتی در ارتباط با چگونگی توزیع شدن داده ها ندارند.
چگونه می توان داده ها را به صورت ناپارامتری تحلیل کرد؟
اولین نکته با توجه به دلایل ذکر شده در بالا توجه به این مطلب است که نمی توان از داده های اصلی در تحلیل استفاده کرد و نمی توان روی داده های خام محاسباتی را انجام داد و یا فرضیاتی در ارتباط با توزیع جمعیت تحت بررسی ساخت. آنچه که در مورد اعداد تولید شده در یک مقیاس امتیاز دهی می توان فرض کرد مانند حالتی است که معلمی مورد استفاده قرار می دهد، بدین معنی که نمرات به گونه ای هستند که به ما اجازه ی نسبت دادن رتبه های ترتیبی به مجموعه ای از داده ها می دهند. در حالت عادی نمی توان در مورد تفاوت میان امتیازهای 24 و 26 نسبت داده شده توسط معلم تصمیم گیری کرد، در حالیکه فقط می توان گفت شخصی با امتیاز 26 نسبت به کسی که امتیاز 24 را به خود نسبت داده است از دقت بالاتری برخودار است. بنابراین امتیازها به داده های ترتیبی هستند، آنها به صورت رتبه هایی مشخص به آزمودنیها نسبت داده می شوند. با بررسی امتیازهای نسبت داده شده به کودکان توسط معلم می توان گفت که مری به عنوان فردی با بیشترین دقت و کریستین با کمترین دقت امتیاز داده شده اند. در حقیقت بر اساس امتیاز های داده شده، رتبه ی ترتیبی شرکت کنندگان مشخص می گردد. در جدول زیر کودکان به ترتیب از کمترین دقت (رتبه 1) تا بیشترین دقت (رتبه 10) رتبه بندی شده اند.
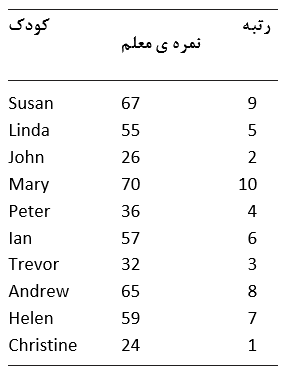
تا زمانی که داده ها ترتیبی هستند، می توان با خیال راحت به اطلاعاتی که از مجموعه ی داده ها به عنوان رتبه ها استخراج شده اند تکیه کرد. در تحلیل رتبه ها نیاز به ساختن هیچگونه فرضیاتی در ارتباط با فواصل و یا توزیع تحت بررسی نیست. در حقیقت کلیه ی تحلیل های ناپارامتری رتبه های بدست آمده از موقعیت های گوناگون متغیر وابسته را مقایسه می کند. می توان به مقایسه رتبه های دختران و پسران پرداخت. چنانچه دختران تمامی رتبه های بالا را دریافت کرده و پسران رتبه های پایین را به خود اختصاص دهند، در واقع این رخداد به نوعی در حمایت از فرض آزمایشی خواهد بود. اینکه چگونه و چه زمانی می توان تصمیم گرفت که کدام یک از مجموعه ی رتبه ها به صورت معنی داری از دیگر مجموعه متفاوت است، بخش اصلی آزمونهای ناپارامتری مختلف است. در بسیاری موارد آماره ها به آزمون های ناپارامتری گسترش پیدا کرده اند و زمانی که فرضیات آزمون های پارامتری برقرار نباشند می توانند به کار گرفته شوند. در جدول زیر معادل ناپارامتری آزمون های معروف پارامتری آورده شده است.
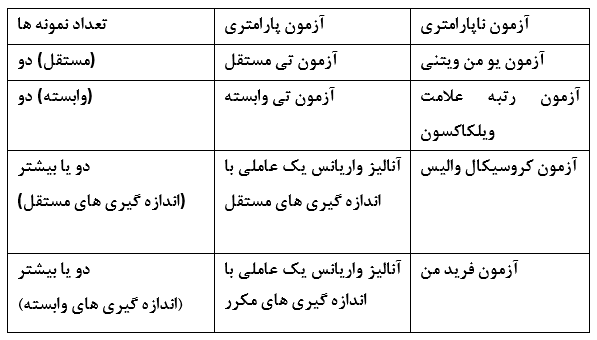
محاسبه رتبه ها
زمانی که در تحلیل های آماری نیاز به رتبه بندی داده ها باشد، به کوچکترین نمره رتبه 1 و رتبه دادن به نمرات را ادامه می دهیم تا اینکه به بیشترین نمره بالاترین رتبه اختصاص داده می شود. در تعدادی از آزمون ها مهم نیست که رتبه بندی از بالا به پایین باشد و یا از پایین به بالا. ترتیب چگونگی رتبه دهی (مترجم: از بالا به پایین و یا بالعکس) زمانی اهمیت پیدا می کند که آخرین رتبه مورد نیاز باشد. از اینرو اینکه عادت به روشی خاص جهت رتبه بندی داشته باشیم می تواند ایده مطلوبی باشد.
این مسئله اغلب زمانی اتفاق می افتد که در یک آزمون بیش از یک آزمودنی نمره ای مشابه دریافت کرده باشند. در این مورد معقول است که رتبه ای مشابه به این افراد داده شود. روشی جهت انجام این کار یافتن تعدادی از آزمودنی ها است که نمره ی خام مشابهی دارند. به عنوان مثال ما این تعداد S را نسبت می دهیم، بنابراین اگر سه آزمودنی نمره ای مشابه داشته باشند s=3. رتبه ای که اختصاص داده می شود r است. اگر پنج داده قبل از نمرات گره خورده باشد بنابراین r=6. فرمولی جهت محاسبه رتبه ی آزمودنی های گره خورده به صورت زیر ارائه می شود:

با مشاهده ی مثال دلیل داده چنین رتبه هایی آسان می شود. اگر نمرات متفاوت بودند رتبه های 6 ، 7 و 8 را به آنها نسبت می دادیم. اما چون مشابه هستند رتبه ای مشترک به آن سه تا داده می شود. رتبه ی بعدی که اختصاص داده می شود برابر خواهد بود با r+s. در مورد مثال ما این رتبه برابر 9 خواهد بود.
گاهی اوقات رتبه ی اختصاص داده شده به امتیازهایی با ارزش یکسان یک عدد صحیح نیست. اگر دو آزمودنی امتیازهایی یکسان داشته باشند و رتبه ی بعدی اختصاص داده شده برابر با 6 باشد، بنابراین به هر دو آزمودنی رتبه 6.5 داده می شود. البته این روش فقط برای امتیازهای گره خورده به کار می رود و کلیه ی رتبه ها از این طریق بدست نمی آیند.
انجام محاسبات با استفاده از رتبه ها
روش هایی برای انجام محاسبات با بکارگیری رتبه ها وجود دارد. از این محاسبات جهت ساختن آزمون های آماری می توان استفاده کرد. محاسبات با استفاده از رتبه ها اغلب ساده تر از نمرات است به گونه ای که اگر ده نمره داشته باشیم ممکن است هر عددی به آنها اطلاق شود در حالیکه در مورد ده رتبه فقط با اعداد 1 تا 10 روبرو خواهیم بود. چنانچه از رتبه استفاده شود تنها با داشتن تعداد نمرات می توان طیف وسیعی از آماره های رتبه ای را بدست آورد. اگر تعداد نمرات برابر با n و R به عنوان رتبه باشد بنابراین:


زمانی که رتبه های گره خورده وجود نداشته باشد زیرا در این حالت نسبت به زمانی که تعداد بیشتری از رتبه های گره خورده وجود دارند، آماره هایی وجود دارند که از اعتبار کمتری برخوردارند.
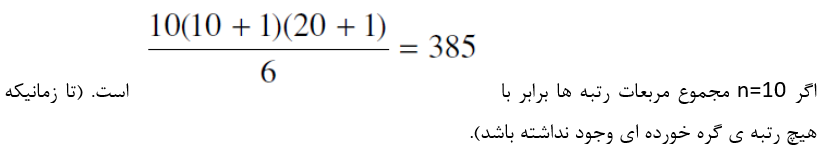
در فصل هایی که در ادامه خواهند آمد طریقه ی چگونگی محاسبات در تحلیل های ناپارامتری داده ها شرح داده می شود.
مترجمین: دکتر هدی کامرانی فر – حسن اسکندری نیا




